Problem Statement
- How would you build an ML system to predict the probability of engagement for Ads?
- Search engine
- Social media platforms
Display media recommendations for a specific user. Type of user feedback includes explicit and implicit feedbacks. The implicit feedback allows collecting a large amount of training data.
Design a Twitter with 500 million daily active users feed system that will show the most relevant tweets for a user based on their social graph.
Key challenages: maximize relevance while minimize latency
The Grad-CAM (Gradient-weighted Class Activation Mapping) is a generalization of CAM and is applicable to a significantly broader range of CNN model families.
The intuition is to expect the last convolutional layers to have the best compromise between high-level semantics and detailed spatial information which is lost in fully-connected layers. The neurons in these layers look for semantic class-specific information in the image.
$$L_{Grad-CAM}^c = ReLU(\sum_k\alpha_k^cA^k)$$
where $$\alpha_k^c = \frac{1}{Z}\sum_i\sum_j\frac{\partial{y_c}}{\partial{A_{ij}^k}}$$
Image preprocessing in Xception model
The image preprocessing process for the Xception model typically includes the following steps:
The K-fold cross validation is to divide the training data into K parts, using K-1 of them for training and the remaining part for testing. Finally, take the average of the testing errors as the generalization error. This allows for better utilization of the training data.
However, I encountered some problems when I was trying two kinds of k-fold cross validation methods. Firstly, we need to understand the significance of data division.
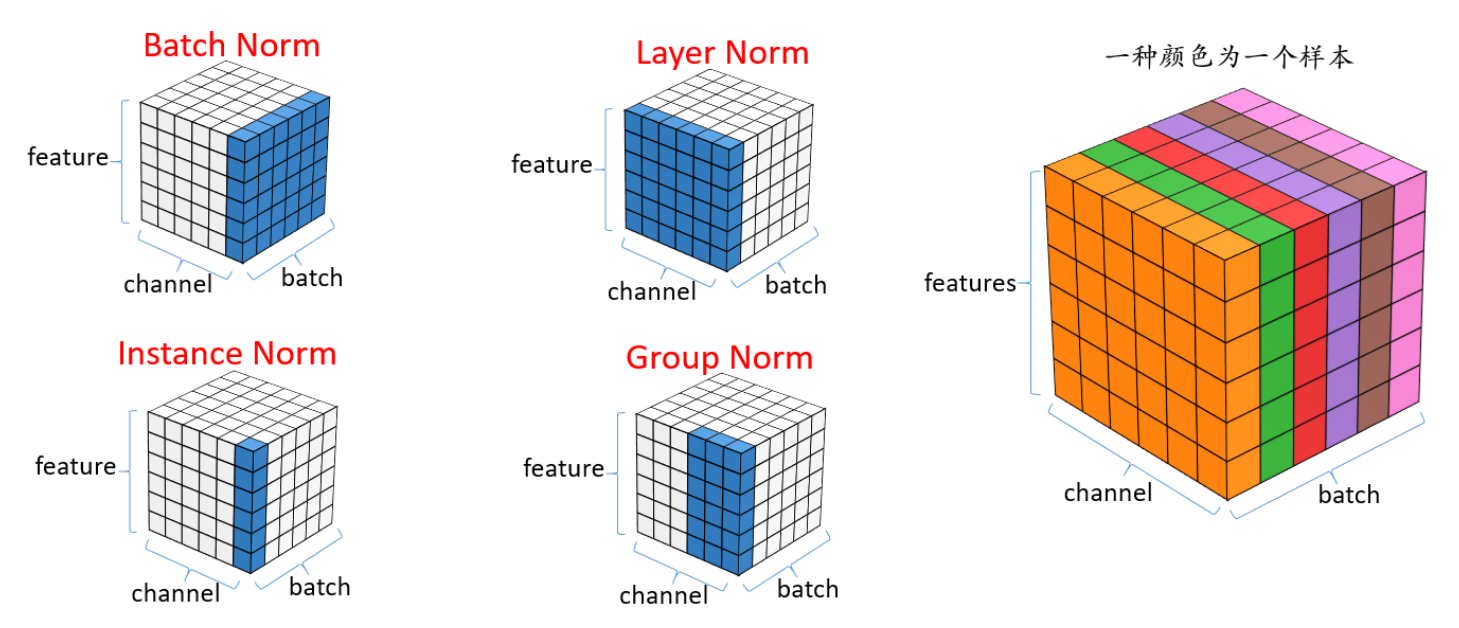
Layer Norm | Batch Norm | Instance Norm | Group Norm