Personalized feed
Problem Statement
Personalized posts/news/other content feed on social media like facebook, instagram, and Linkedin, to maintain user engagement.
Clarifications or Assumptions
- assume the motivation for a personalized feed is to keep users engaged with the platform
- refreshed activity consists of both unseen posts and posts with unseen comments
- a post contains textual content, images, video, or any combination
- the system should place the most engaging content at the top of timelines
- Is there a specific type of engagement we are optimizing for?
- I assume users can click, like, share, comment, hide, block another user, and send connection requests
- for example, liking a post is more valuable than only clicking it
- our system should consider major reactions when ranking posts
- the system should display the ranked posts in less than 200 milliseconds (ms).
- 3B ADU, 2B ADU who check their feeds twice a day
Frame as an ML business objective
Business Objective
The objective of the system is to increase user engagement.
ML Objective
Maximize a weighted score based on both implicit and explicit reactions
- implicit (dwell time or user clicks etc.) and explicit reactions (likes, shares, and hides etc.)
- input: a user; output: a ranked list of unseen posts or posts with unseen comments sorted by engagement score.
Pointwise Learning to Rank (LTR) is a choice for us to rank personalized feeds based on engagement scores.
Data Engineering
- User
- Posts
- User-post interactions
- Friendship
Feature Engineering
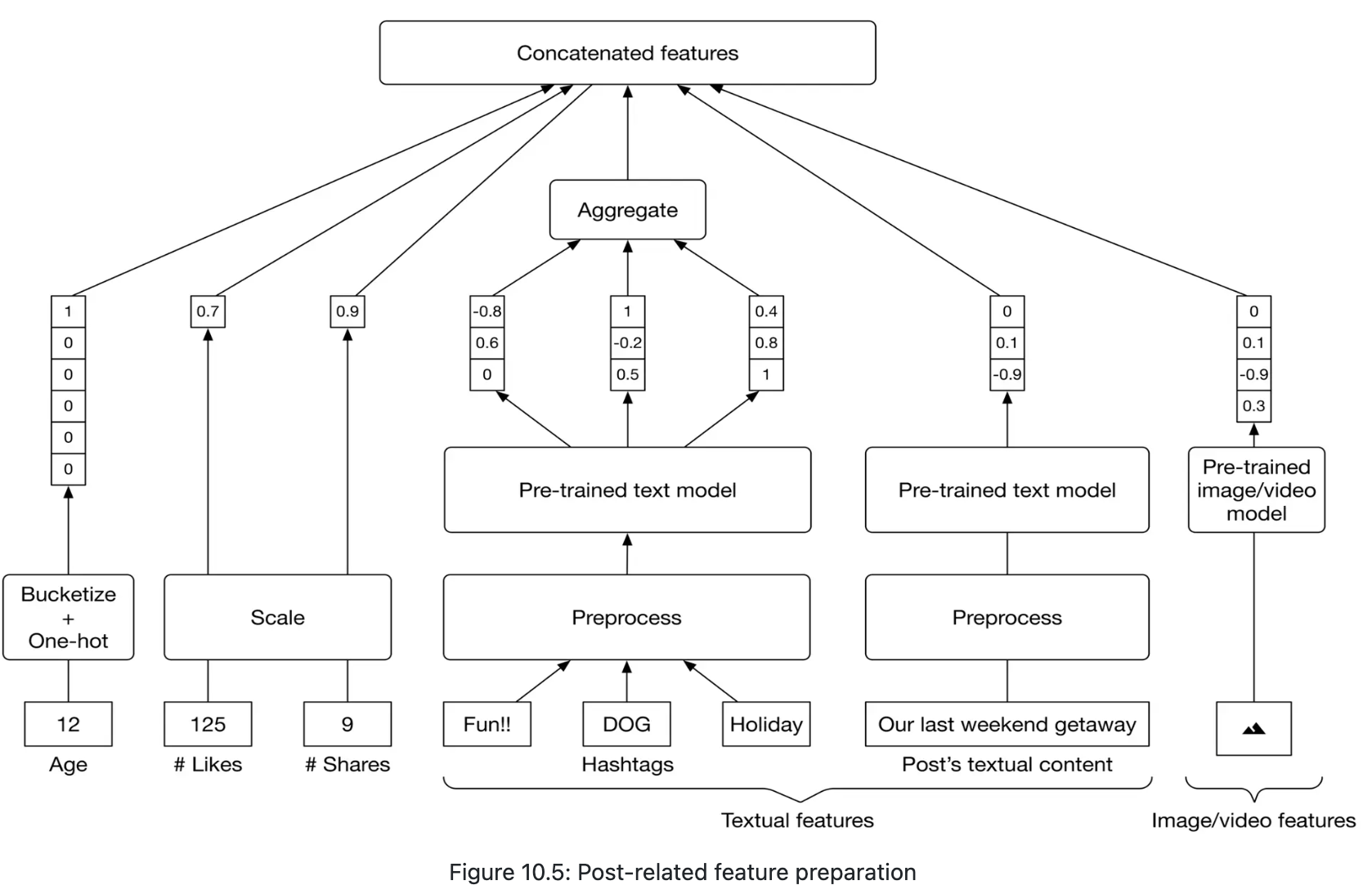
- Post features
- textual content
- images or videos
- reactions, converted into numeric values
- hashtags
- Tokenization
- contain multiple words, Viterbi
- Tokens to IDs
- Hashtags evolve quickly
- Vectorization
- simple text representation methods such as TF-IDF or word2vec
- Transformer-based models are useful when the context of the data is essential, faster and lighter text representation methods are preferred here
- Tokenization
- post’s age
- Users tend to engage with newer content
- Bucketize into categories + one-hot encoding
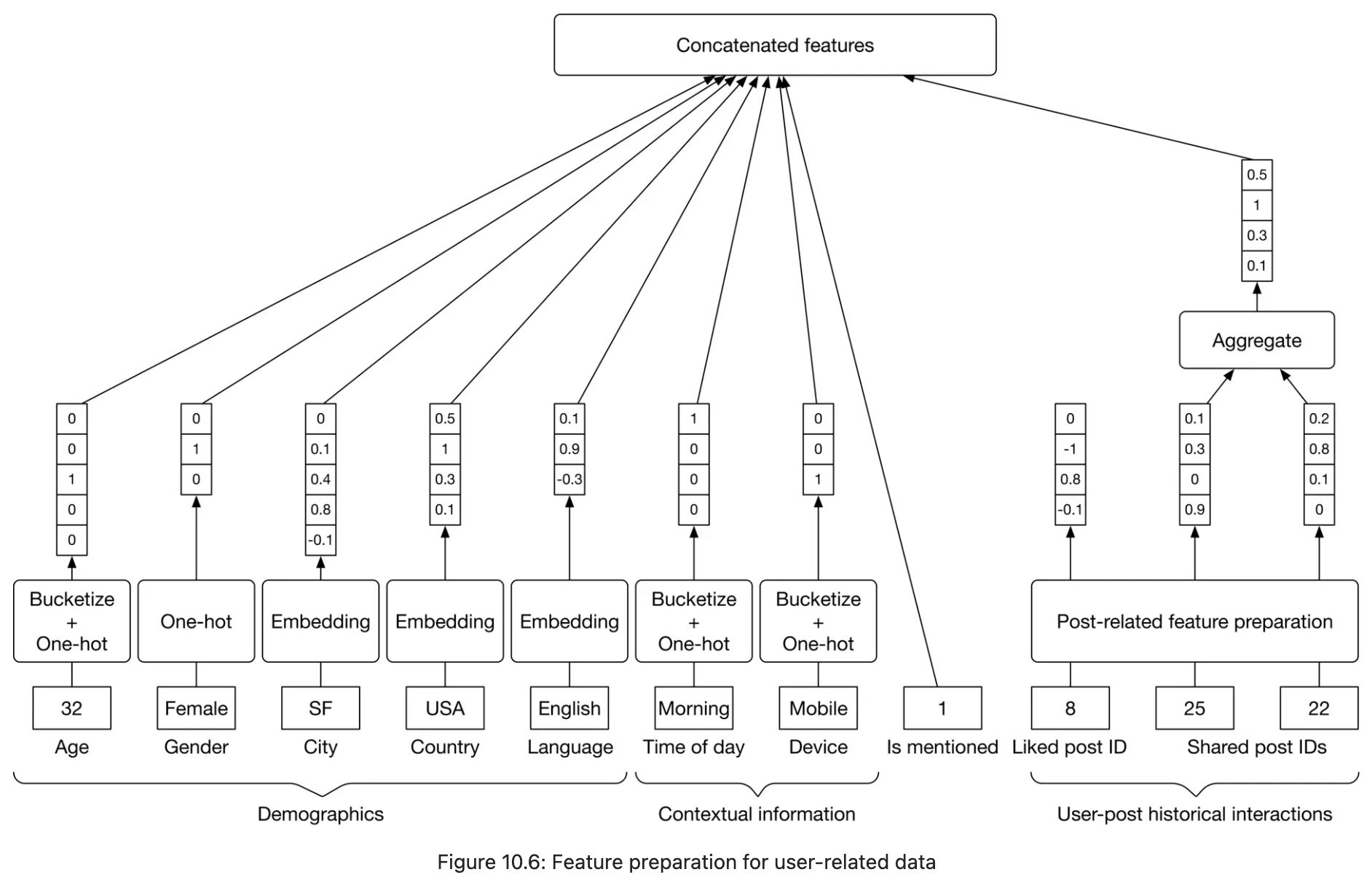
- User features
- Demographics: age, gender, country, etc
- Contextual information: device, time of the day, etc
- User-post historical interactions
- Being mentioned in the post
- User-author affinities
- Like/click/comment/share rate
- Length of friendship
- Close friends and family
Modeling
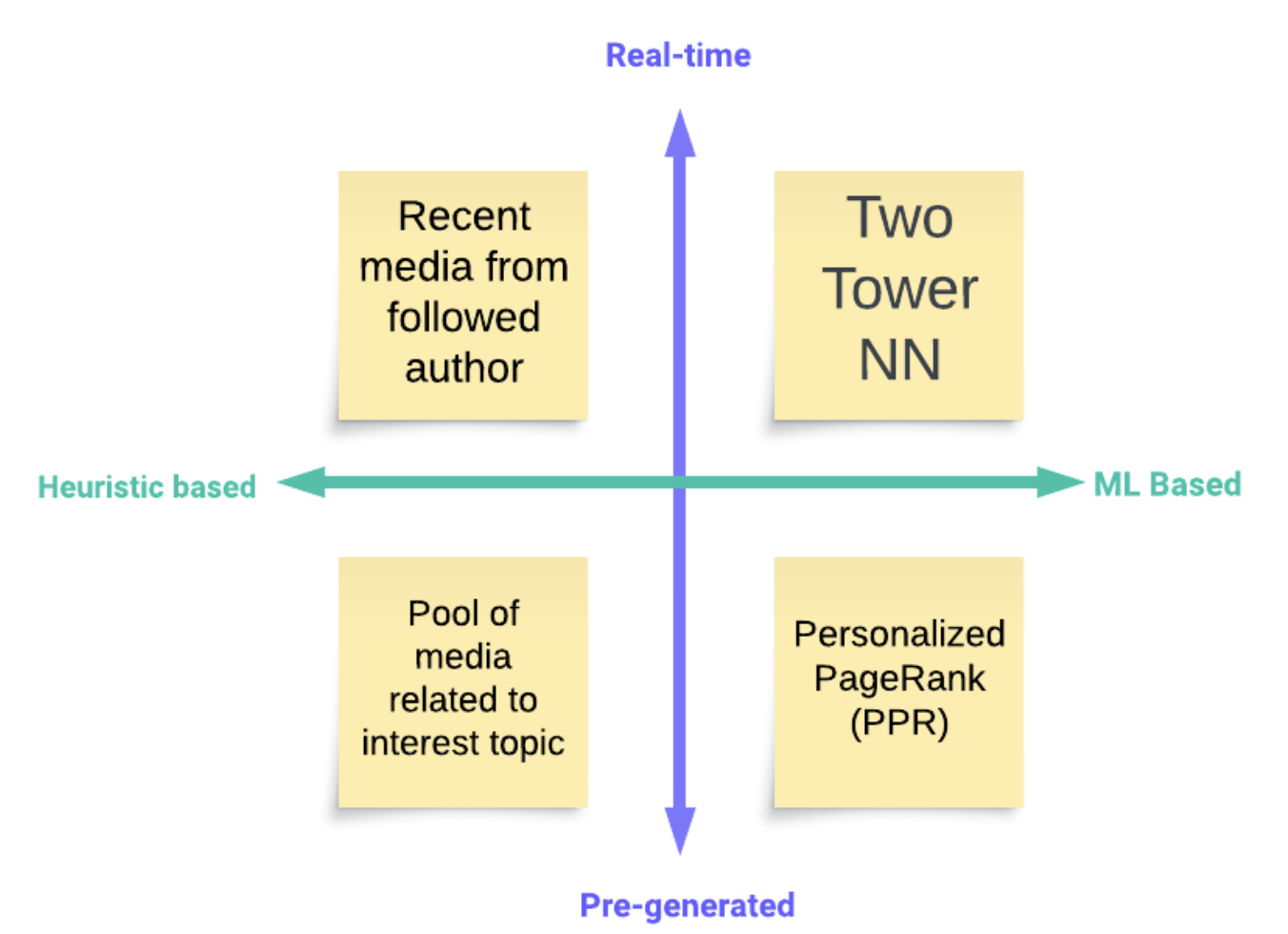
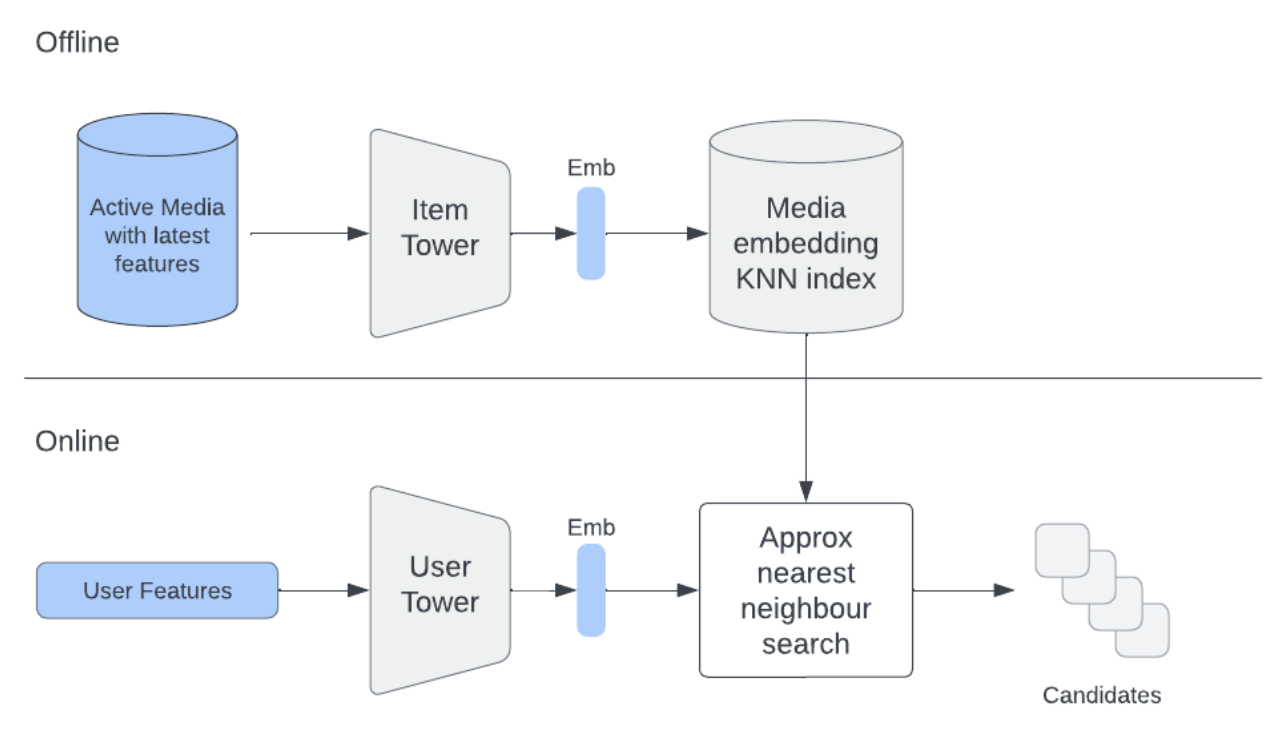
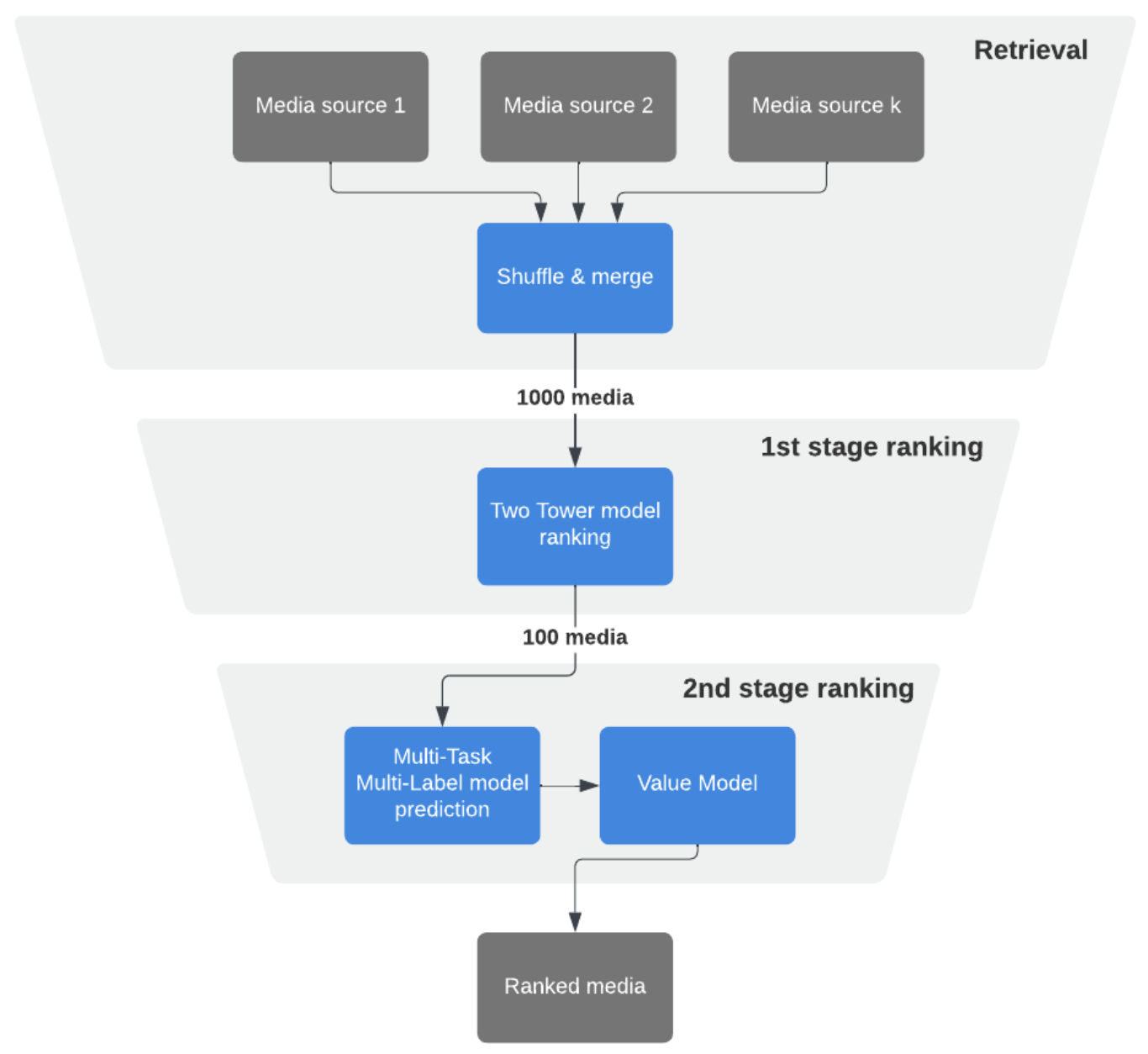
Candidate generation
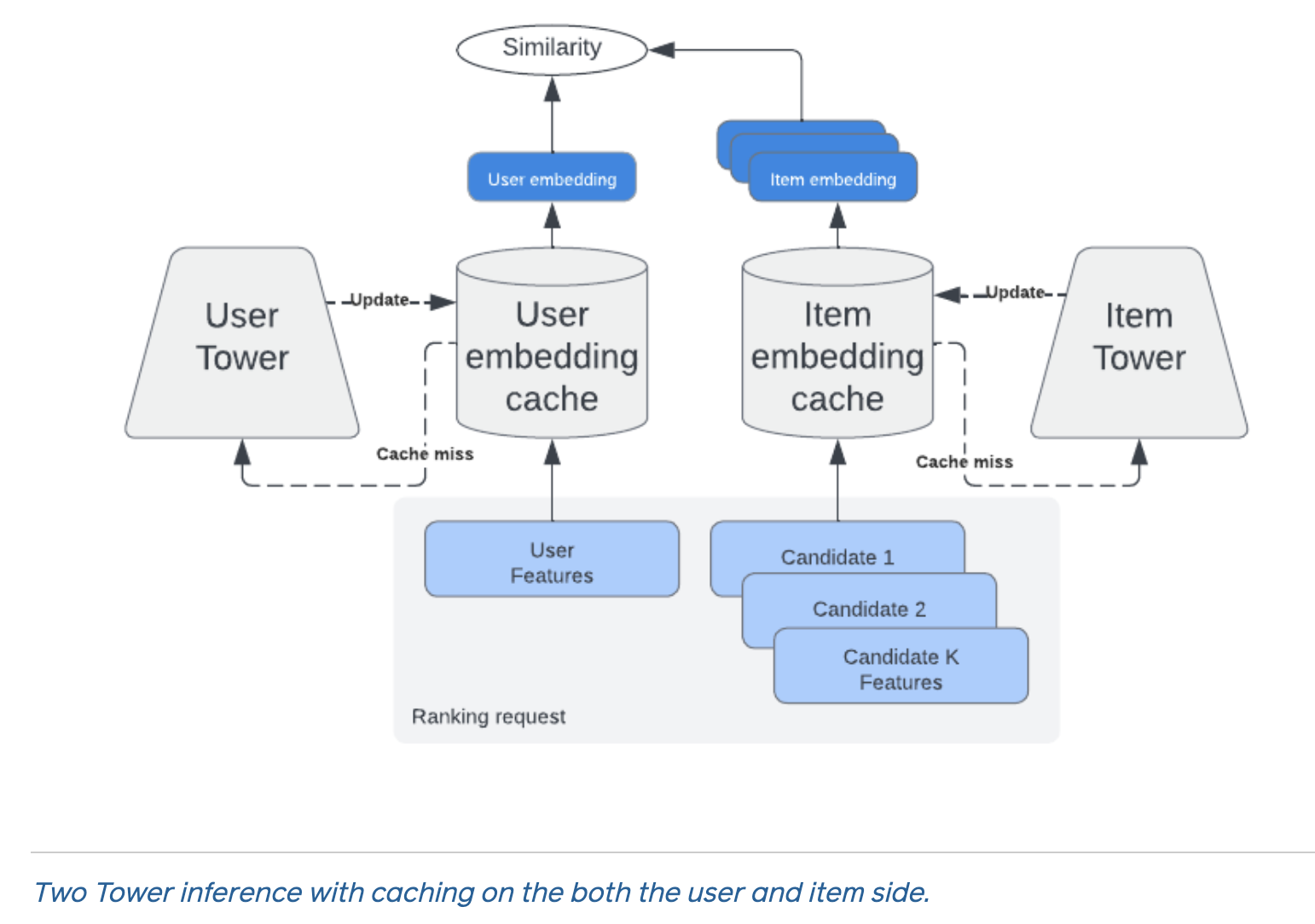
- Cached embeddings to improve efficiency
- pre-compute and store items embeddings into a service (FAISS/Milvus/Elastic KNN) offline to support online approximate nearest neighbors (ANN) search
- During online retrieval we use the user tower to generate user embedding on the fly
Rule of thumb: If your score can be written as sim(u(user_only), v(item_only)), it’s retrieval-safe and ANN-friendly.
- the retrieval model can’t consume user-item interaction features (which are usually the most powerful) because by consuming them it will lose the ability to provide cacheable user/item embeddings.
- non-decomposable, pairwise features φ(user,item), push it to ranking stage
Lightweight ranker
- learning objective is different from the retrieval stage:
- Retrieval is trained for recall/coverage; pre-rank is distilled for “what the heavy model would keep”
- PSelect = { media in top K results ranked by the second stage}
- the only reason we use Two-Twoer NN again because of its cacheability property and scale/latency/throughput tradeoffs
- view this approach as a way of distilling knowledge from a bigger second-stage model to a smaller (more light-weight) first-stage model
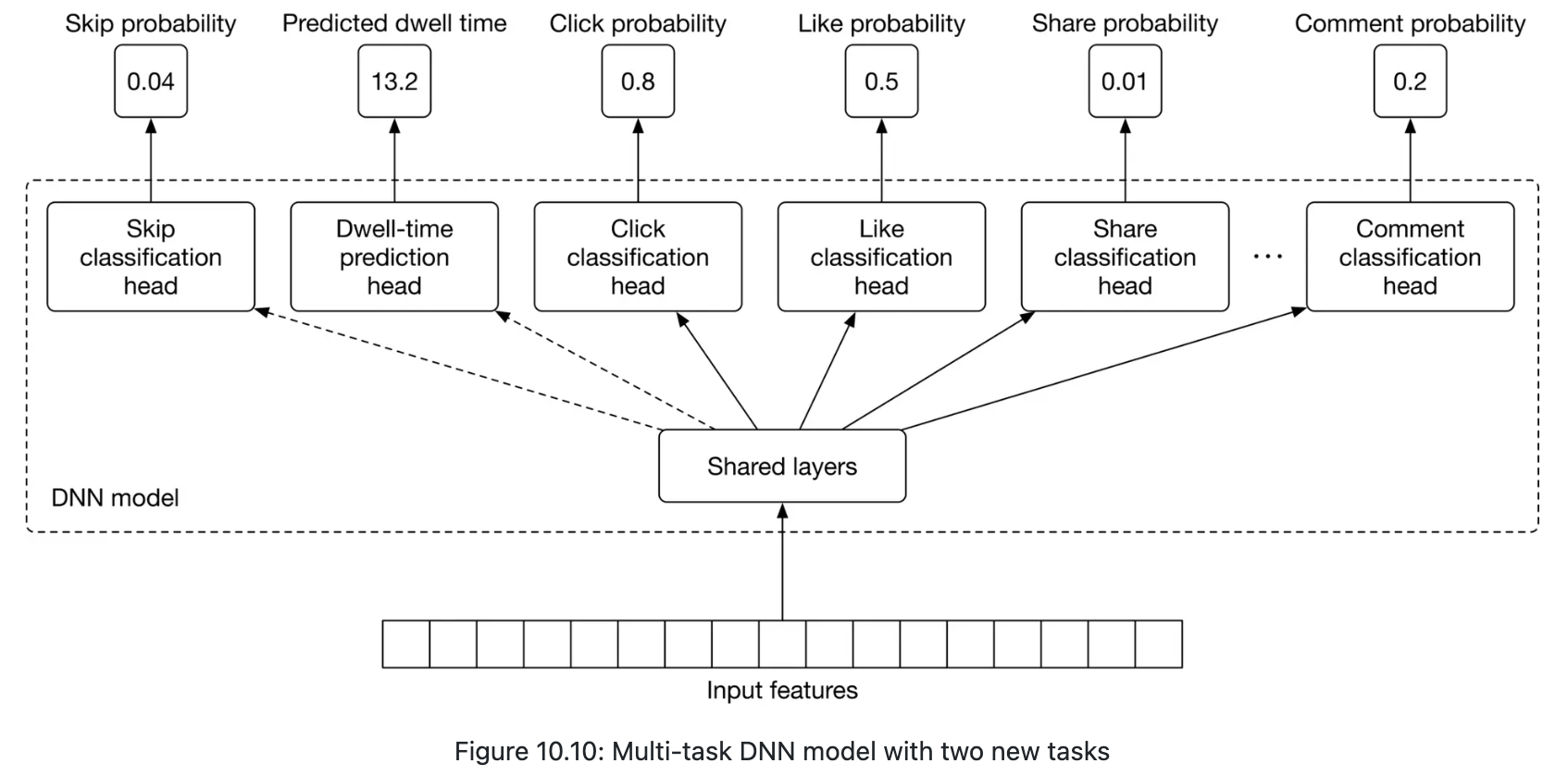
Heavey ranker
- multi-task multi label (MTML) neural network model.
- Value Model (VM): Expected Value = W_click * P(click) + W_like * P(like) – W_see_less * P(see less) + etc.
For both stages we choose to use neural networks
- it’s important to be able to adapt to changing trends in users’ behavior very quickly. Neural networks allow us to do this by utilizing continual online training, meaning we can re-train (fine-tune) our models every hour as soon as we have new data.
- a lot of important features are categorical in nature, and neural networks provide a natural way of handling categorical data by learning embeddings
Re-ranker
- filter-out/downrank some items based on integrity-related scores
- shuffle items based on some rules
Loss function
- The overall loss is computed by combining task-specific losses
- use a binary cross-entropy loss for each binary classification task
- a regression loss such as MAE, MSE, or Huber loss for the regression task (dwell-time prediction).
Improving the DNN architecture for passive users (dwell-time and skip), since the current multi-task DNN model will predict very low probabilities for all reactions, since they rarely react to posts.
Evaluation
Offline metrics
- ROC-AUC for overall performance
Online metrics
- Click-through rate (CTR)
- Reaction rate
- Total time spent
- User satisfaction rate found in a user survey
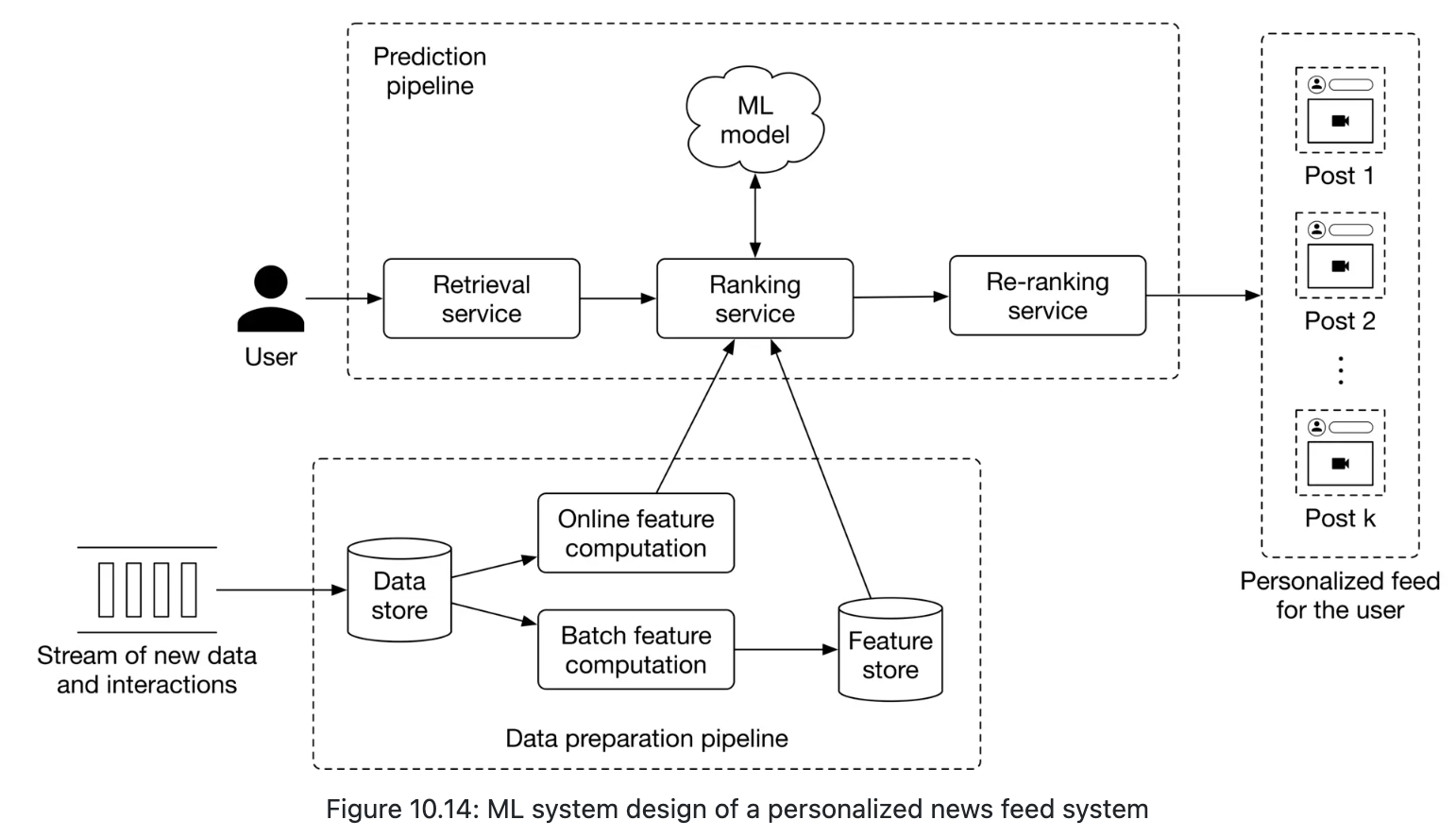
Serving
References ⭐
Personalized feed