Event Recommendation System
Problem Statement
Design a location-based event recommendation system similar to Eventbrite’s or Yelp, which should personalize the experience.
Clarifications or Assumptions
- if it is an event recommendation, it should be considered as one-time occurance, and then expires
- can user becomes friends on the platform?
- third-party API accessible (Google Map etc. for distance and travel time calculation)?
- do we have initial annotated data?
- Assume 1M ADU?
- Assume 1M events per month?
Requirements
- Functional Requirement
- location proximity
- Personalization
- contextual relevance
- Non-Functional Requirement
- Low latency, high QPS
- Freshness SLAs, incorporate real-time info
- diversity, fairness
- throughput, scale
- tooling
Frame as an ML business objective
Business Objective
- Bad Solution
- Maximize click-through rate (CTR)
- Good Solution
- Maximize long-term user-to-business satisfaction and engagements
- For events, it could be to increase ticket sales, maximize the number of event registrations
- For yelp, it could be a weighted combination of conversion rate (calling, joining waitlist, reservation) + CTR
ML Objective
A personalized ranking problem, or a Learning to Rank (LTR) problem, which stated as predicting the probability of a positive user-business interaction.
Essentially, the system should assign a relevance score to each (user, business) pair in context and use that for ranking.
LTR
Let’s briefly go through three LTR approaches:
Pointwise
- predict the relevance between the query and the item independently
- using classification or regression methods
Pairwise
- takes two items and predicts which item is more relevant to the query
Listwise
- predict the optimal ordering of an entire list of items
We use pointwise approach for this problem, which takes a single event at a time and predicts the probability that the user will register for it.
High-level Design
Still open to use the typical pipeline candidate generation -> ranking -> post-processing
Candidate generation
- several retrieval sources
- ANN search (approximate nearest neighbors)
Lightweight ranker
- more precise than retrieval, and with more features
Heavy ranker
- a full-complexity model with all available features
Post-processing (reranking)
- no more new ranking between candidates
- adjust the ranked list for business rules or diversity
- removing near-duplicates
- enforcing category diversity
- inserting guaranteed sponsored items if needed
- minor re-ordering
Data Engineering
- User
- explicit profile data (age, gender, stated preferrence, time zone, language etc.)
- derived behavior signals
- comments/reviews if they write many
- average ratings they given if any
- Events/items
- Categorical attributes (category tags etc.)
- Numerical attributes (rating, number of reviews, prices, etc.)
- Textual attributes (description, recent reviews etc.)
- Location/timestamp/time zone
- Friendship (if accessible)
- basic info like timestamp when friendship was formed
- ‘count of friends who rated this business’ or ‘average rating given by friends’
- Interactions
- it captures the relationship between this user and this business
- User’s prior interaction with this business
- Interaction context match
- it captures the relationship between this user and this business
- Context
- Any situational info about current request
- user current location/the location they are browsering
- Time of request
- seasons (holidy etc.)
- Any situational info about current request
- Graphs (in terms of yelp)
- often require offline computation to build a feature store
- user-business graph (hot among similar users, similar_user_reviewed)
- business-business graph (where edges mean common reviewers or similar tags)
Class imbalance
- Use focal loss or class-balanced loss to train the classifier
- Undersample the majority class
Feature Engineering
In terms of one-time occurance events, they are more challenging than traditional recommendations.
- No consumption after the event ends
- short-lived, and not many historical interactions available
Location-related features
- How accessible is the event’s location? (walk score, walk similarity, etc., we could use bucketize into score categories)
- Is the user comfortable with the distance?
- the distance between the user and the event, could be encoded using ‘Bucketize + One-hot’
- distance similarity, difference between the distance to an event and the average distance (in reality, the median or percentile range can be used) to events previously registered by the user.
Time-related features
- How convenient is the time remaining until an event?
- The remaining time until the event begins.
- Remaining time similarity
- The estimated travel time
- Estimated travel time similarity
- Are the date and time convenient for the user?
Social-related features
- How many people are attending this event?
- Features related to attendance by friends
- Is the user invited to this event by others?
- Is the event’s host a friend of the user?
- How often has the user attended previous events created by this host?
User-related features
- Age (bucketize+one-hot) and gender (One-hot)
Event-related features
- Price of event, bucketize into a few categories
- Price similarity
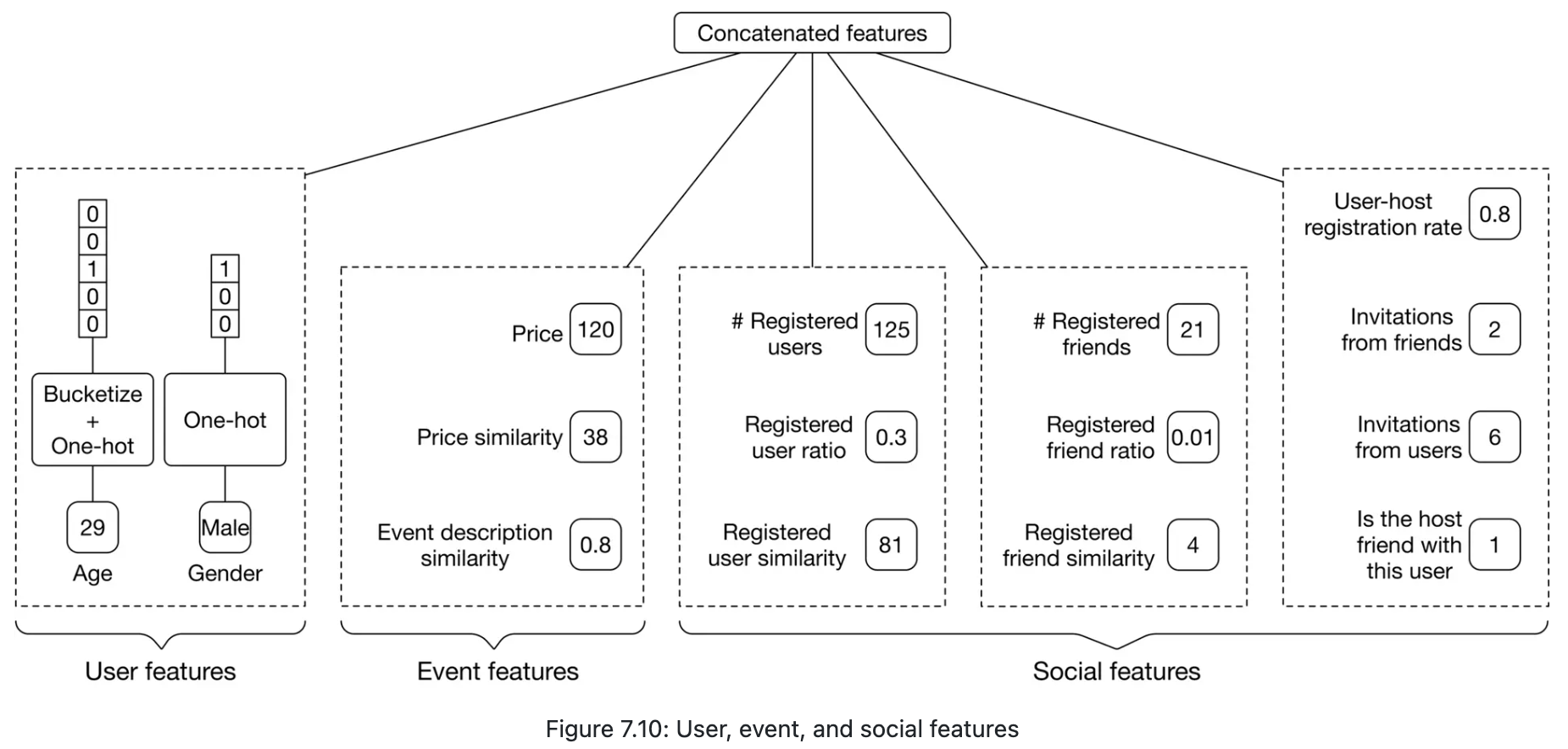
Feature Update Cadence
- Batch vs. streaming features
- Batch features (user profile, graph-based info, textual attributes) could be computed daily or weekly offline via pipeline jobs
- Streaming features (location, time, session interaction) are fetched on the fly and we should mantain an in-memory store for it
- Nearline features (trending_score if an event suddenly gets a spike)
- Feature computation efficiency
- For example, we can pass both locations to the model as two separate features, and rely on the model to implicitly compute
- Using a decay factor
- for features that rely on the user’s last X interactions. A decay factor gives more weight to the user’s recent interactions/behaviors.
Modeling
Candidate generation
we might implement multiple strategies in parallel
- A two-tower neural retrieval model
- train on historical user-business interactions to learn collaborative filtering signals
- A content-based retrieval using filters
- category matching etc.
- maintain a vector-database
- ensures well-rated, locally popular options are always considered, even if the user is new (cold start)
- pre-compute frequent queries
- category matching etc.
- A graph-based retrieval
- item-item graphs
- business similarity graph to help surface exploratory items
Lightweight ranker
This stage scores candidates with a more refined model to eliminate obviously irrelevant items using dozens of features that are inexpensive to compute.
- Gradient Boosted Decision Tree (GBDT), (e.g. XGBoost or LightGBM)
- Inexpensive features
- global features (business average rating, popularity)
- simple user-business interactions (distance)
- some personalization signals
Heavy ranker
- Multi-task structure, perhaps top layer fork into multiple heads
- using multi-task loss during training, and combine them into a final relevance score during inference
Re-ranking/Post-Processing
- enforce diversity rules
- handle business constraints (closed, duplicated or blacklisted)
- insert sponsored listings (ads)
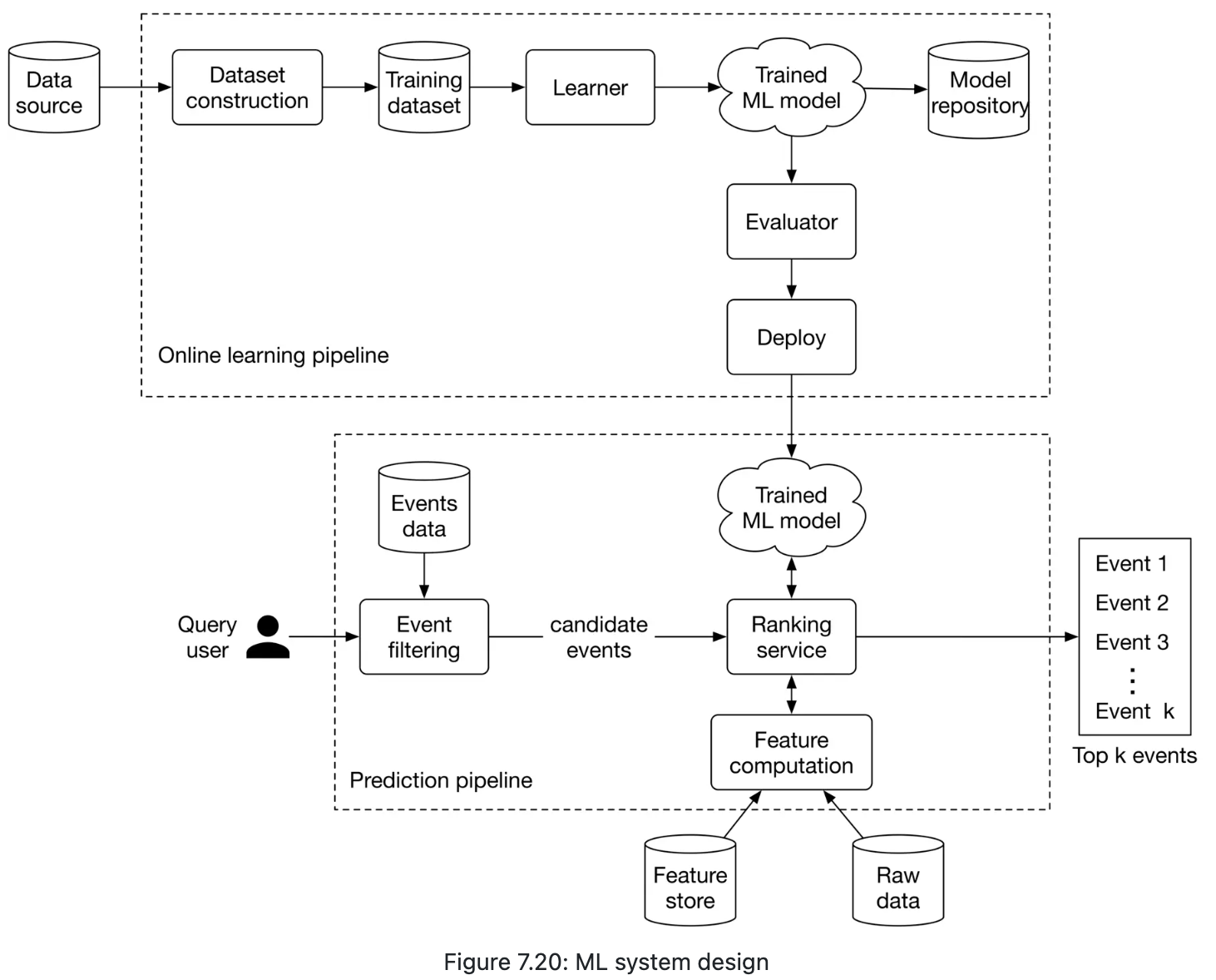
Online learning: it must be continuously fine-tuned to adapt to new data.
Evaluation
Online metrics:
- Click-through rate (CTR)
- Converstion rate
Offline metrics:
To evaluate the ranking system, we should consider:
- Bad Solution:
- Recall@k or Precision@k: do not consider the ranking quality of the output
- MRR: focues on the rank of the first relevant item in the list, which is suitable in systems where only one relevant item is expected to be retrieved
- Good Solution:
- nDCG: works well when the relevance score between a user and an item is non-binary
- mAP: works only when the relevance scores are binary
Deep Dive
Cold Start strategies
Batch v.s. Streaming features
References ⭐
Event Recommendation System
https://janofsun.github.io/2025/08/30/Location-based-Recommendation-System/