Harmful Content Detection
Problem Statement
Harmful content detection such as illicit-goods (weapon sales/prohibited medicine) offers to sell/facilitate procurement, violence, nudity, and hate speech.
Clarifications or Assumptions
- Text only or multi-modality?
- What happens if we find harmful content?
- What are the consequences of false positives and false negatives?
- How quickly do we need to detect harmful content?
- Do we have data available for the initial training or will we need to cold start?
- How many posts are made per day?
- How common are harmful posts?
Frame as an ML Business Objective
Bad Solution
- Maximize the amount of harmful content removed
- The model is going to flag as much content as possible, regardless of wheher it’s actually harmful
- Maximize the accuracy of our model
- accuracy is a poor proxy here and subject to class imbalance
- Accuracy is an internal metric, not a user/business outcome
Good Solution
- Minimize the number of successful user reports of harmful content
- Minimize the number of views of harmful content, subject to precision guardrails
ML Objective
Binary classification overall: harmful or not, but with multi-label subtasks.
High-level Design
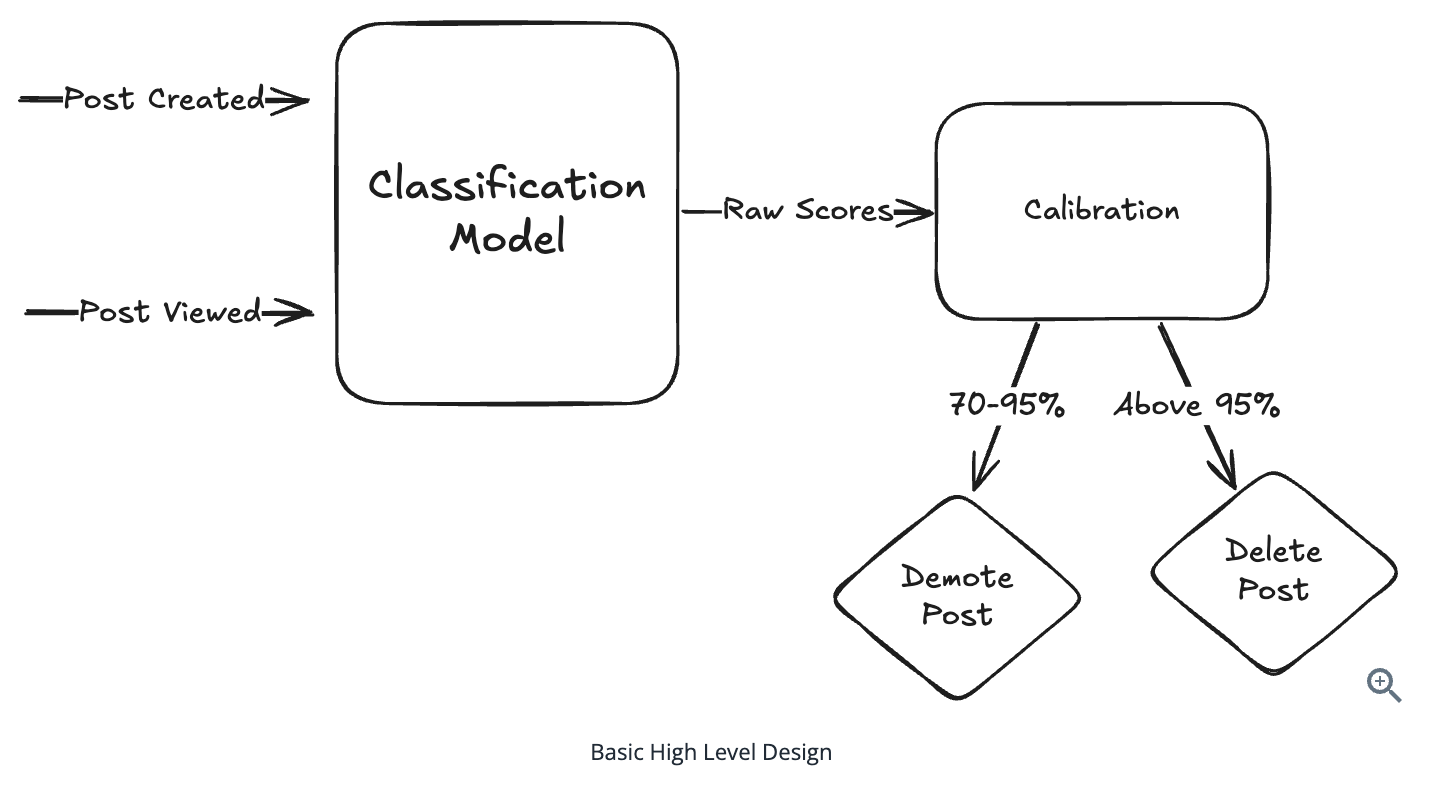
Data Preparation
Supervised Data
- A small amount of labelled data for initial training
- Have access to fresh labelled examples to tackle Data Drift (basically data is out-of-date and the model does not perform well on the latest dataset)?
- NSFW (Not safe for work) datasets available online
- Features are not platform-specific
Semi-Supervised Data
- User reports as decent proxy labels
- We could expect that the volume of user reports would be significantly higher than the amount of labelled data
Self-Supervised Data
- User comments
Class Imbalance
- Use a combination of balanced sampling during training and loss weighting to fine-tune the precision-recall tradeoff
Feature Engineering
Content Features
- The concatenated text input including the post body, hashtags, etc.
- Text preprocessing (normalization/tokenization)
- Vectorization
- ML-based BERT variant (DistilmBERT)
- BERT takes a long time to produce the text embedding, not ideal for onlie predictions
- BERT was trained on English-data only
- Statistic-based Bow or TF-IDF (bad idea)
- ML-based BERT variant (DistilmBERT)
- A collection of images attached to the post
Behavioral Features
- How many comments that signal harmful content were there?
- How many negative reactions (angry reactions, hides, etc.) have been made on the post
- What’s the ratio of shares to views?
Noted: Behavioral Features are fast-moving and subject to change, so modelling them as simple numeric signals is a good way to keep signals simple.
For example, a simple solution is to use ratio like negative_reactions_per_view and shares_per_view which will naturally correct for the age of the post
- [Q] Features is unstable even when the denominator is very small or zero?
- [Q] How do we include these features in our training set?
- [Q] When do we trigger (re-)classification of the model?
Creator Features
- User Embeddings from user’s profile
- Bad Solution: simple embedding model
- Cold start problem
- Data Sparsity
- Overfitting
- Good Solution:
- Bad Solution: simple embedding model
- User Contextual Features
- record real-time tallies of important signals
Modeling
Benchmark Models
- Logistic Regression
- Lightning fast, explainable to give us a good starting point
- There’s going to be a lot of potentially harmful content that it fails to detect
- Because it assumes that all features contribute independently and linearly to the probability of harm.
Model Selection
Requirements:
- Handle multiple modalities
- Capacity to incorporate behavioral and user features
- Efficient inference to handle 1B posts per day
- Ability to update predictions as new behavioral data arrives
Noted:
This should be a multi-label task, not a multi-class task, we shoudl not apply a softmax to assign probabilities, because harmful content can easily have multiple classes simultaneously.
- Late Fusion
- Process text and images through separate encoders
- Concatenate their embeddings along with behavioral and user features
- Pass the combined representation through a simple classification model, like an MLP (multi-layer perceptron).
- To allow some interaction between modalities.
- The main drawback is that the interactions between modalities are limited to the final layers, which might miss important cross-modal patterns.
- Multi-Modal Classifier
- True multi-modal learning with attention between all modalities
- Ability to handle missing modalities naturally
- Strong performance on zero-shot and few-shot tasks
- Efficient handling of behavioral features through attention mechanisms
- The main challenges are computational cost and complexity.
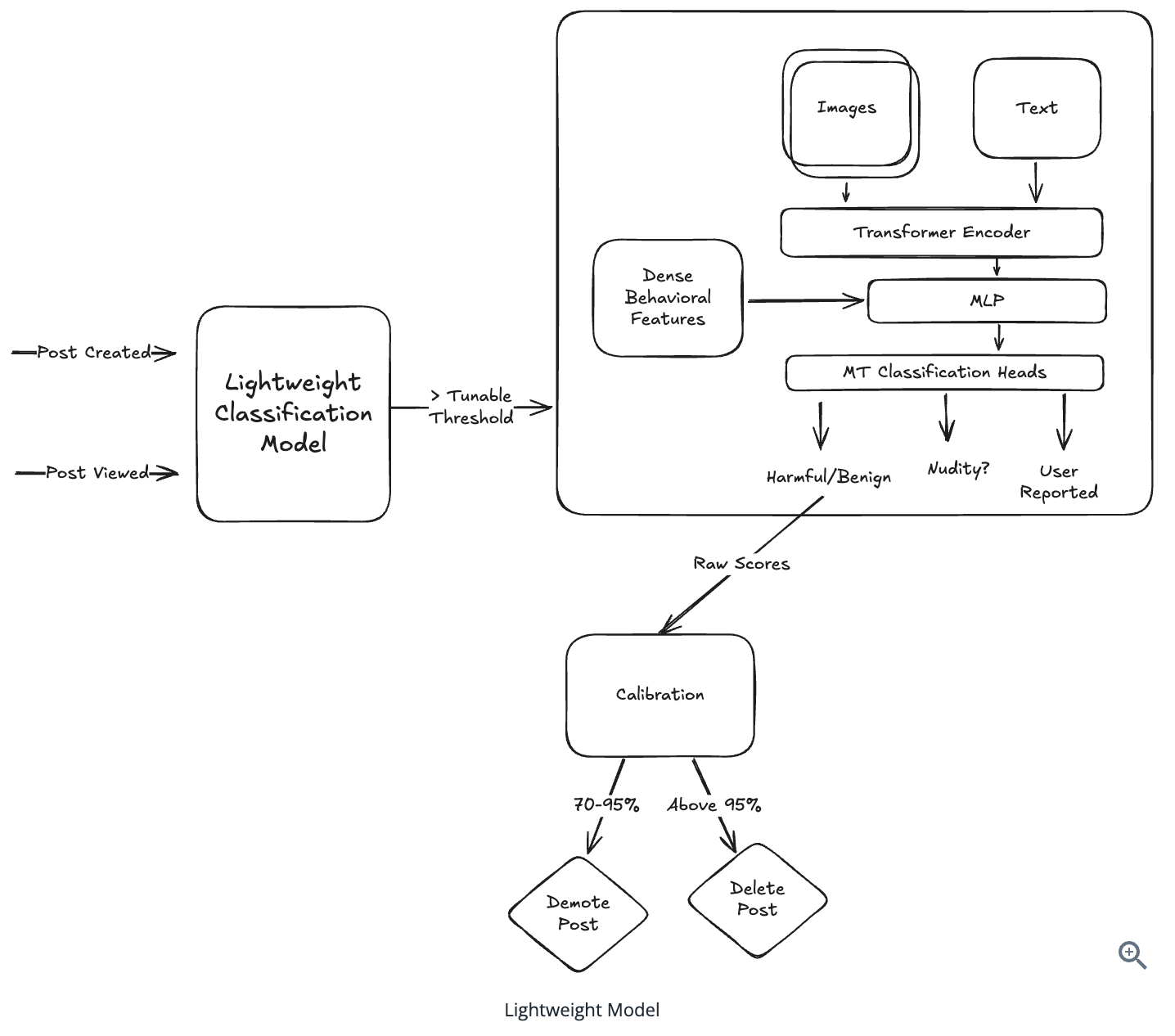
Model Architecture
Multi-modal Encoder:
- A vision transformer (ViT) for processing image patches
- A text tokenizer and encoder for processing the post body, hashtags, etc.
- Cross-attention layers to combine modalities
- Additional embedding layers for behavioral and user features
Lightweight Update Network:
- A small network that can efficiently merge dense, behavioral inputs with the heavy content-specific embeddings
- Takes the original model’s embedding and new behavioral features as input
Classification Heads:
- Multiple classification heads for different tasks we’ll engineer (talk about this in a second)
- Shared representation layers to leverage common patterns
- Calibration layer to ensure precision requirements are met
Loss Function
L = α * L_primary + β * L_reports
Primary Task
L_primary = BCE(y_true, y_pred) * min(log(1+views), c)
- Binary cross-entropy
- View-weighted Loss
- Bad Solution: simply weight by the raw views of the content, views are power-law distribution, causing the loss function be dominated by the high-view content
- Good Solution: add a small logarithmic term, and set an upper cap
cto keep the weight bounded
Report Prediction
L_reports = MSE(report_rate, predicted_report_rate)
Noted: A common challenge in training multimodal systems is overfitting.
For example, when the learning speed varies across different modalities, one modality (e.g., image) can dominate the learning process.
Two techniques to address this issue are gradient blending and focal loss.
Inference and Serving
Challenges:
- Scaling the compute necessary for 1B posts/day
- Quantize the model
- Further optimize by employing caching for our encoders
- Implementing a two-stage architecture for this problem
- This lightweight model serves as a filter to quickly identify obvious non-violations
- Heavier model for only the content that requires deeper analysis
- Triggering the model at the appropriate time
- be able to re-trigger the model when important events happen
Evaluation
Online Evaluation
- Prevalence
- Proactive rate
- User reports per harmful class
Offline Evaluation
- PR-AUC
- ROC-AUC
- Recall@Precision95
References ⭐
Harmful Content Detection
https://janofsun.github.io/2025/08/29/Harmful-Content-Detection/