Self-driving Image Segmentation
Problem Statement
Design a self-driving car system focusing on its perception component (semantic image segmentation in particular)
Subtasks
- Object detection
- Semantic segmentation
- Semantic segmentation can be viewed as a pixel-wise classification of an image.
- Instance segmentation
- It combines object detection and segmentation to classify the pixels of each instance of an object.
- Scene understanding
- Movement plan
Metrics
Component level metric
- Goal: Higher pixel-wise accuracy for objects belonging to each class.
- IoU (Intersection over Union)
- This will be used as the offline metrix.
- $IoU = \frac{|P_{pred}\cap P_{gt}|}{|P_{pred}\cup P_{gt}|}$
- “area of overlap”: means the number of pixels that belong to the particular class in both the prediction and ground-truth
- “area of union” refers to the number of pixels that belong to the particular class in the prediction and in ground-truth, but not in both (the overlap is subtracted).
- The mean IoU is calculated by taking the avaerage of the IoU for each class
End-to-end metric
- Manual intervention
- Simulation errors
Architecture
- Overall architecture for self-driving vehicle
- The object detection CNN detects and localizes all the obstacles and entities
- Drivable region detection CNN: Action predictor RNN is information that allows it to extract a drivable path for the vehicle.
- Semantic image segmentation (from raw pixel-wise boundaries)
- The object detection CNN detects and localizes all the obstacles and entities
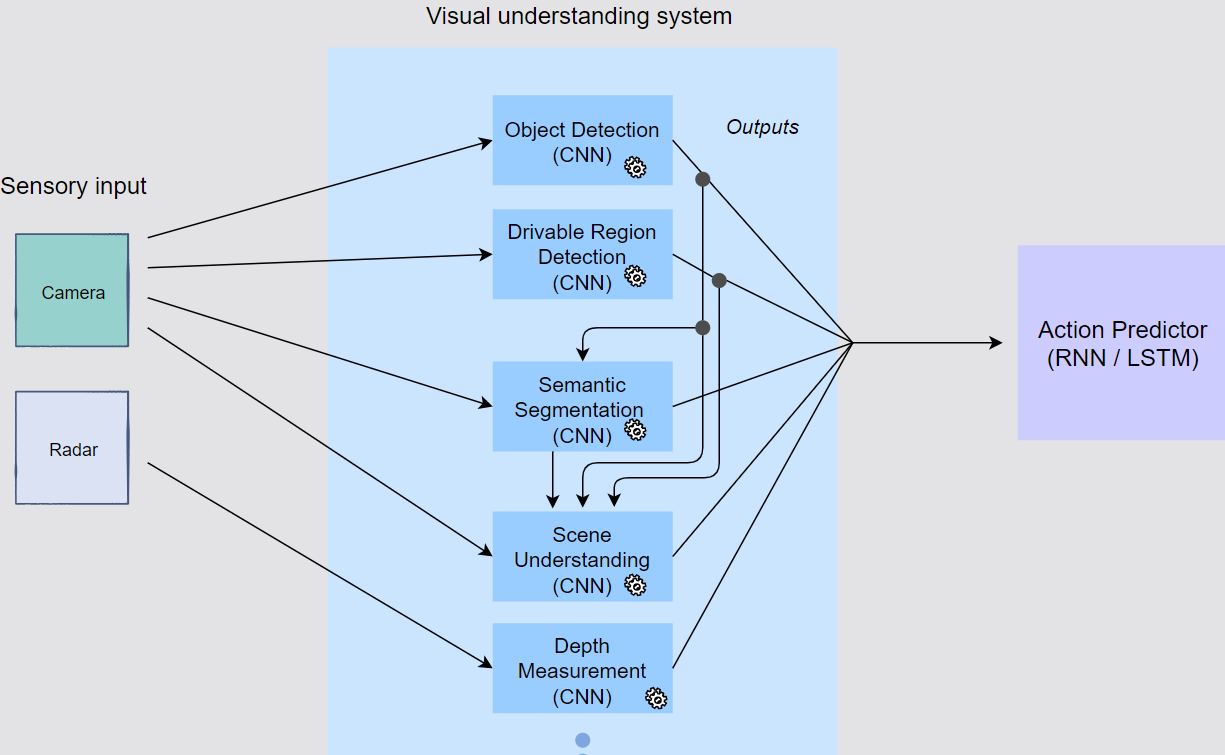
- System architecture for semantic image segmentation
- The real-time driving images are captured and manually given pixel-wise labels.
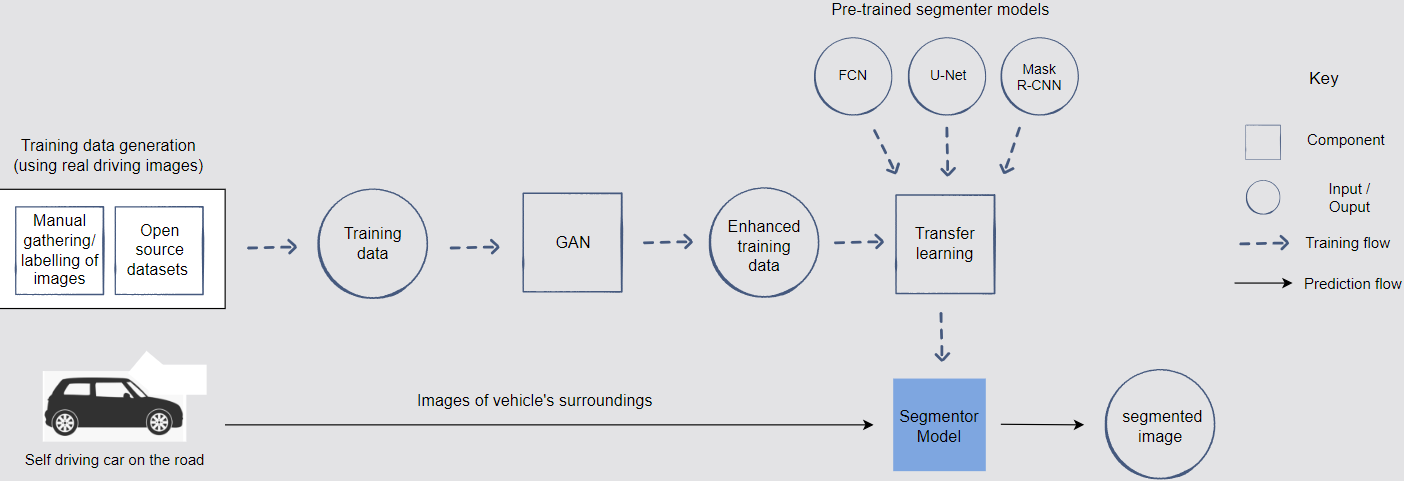
Training Data Generation
- Human-labeled data
- Open Source dataset
- Training data enhancement through GANs
- Generating new training images
- Ensuring generated images have different conditions (e.g. weather and lighting conditions)
- Image-to-image translation (cGANs)

- Targeted data gathering
Modeling
- SOTA segmentation models
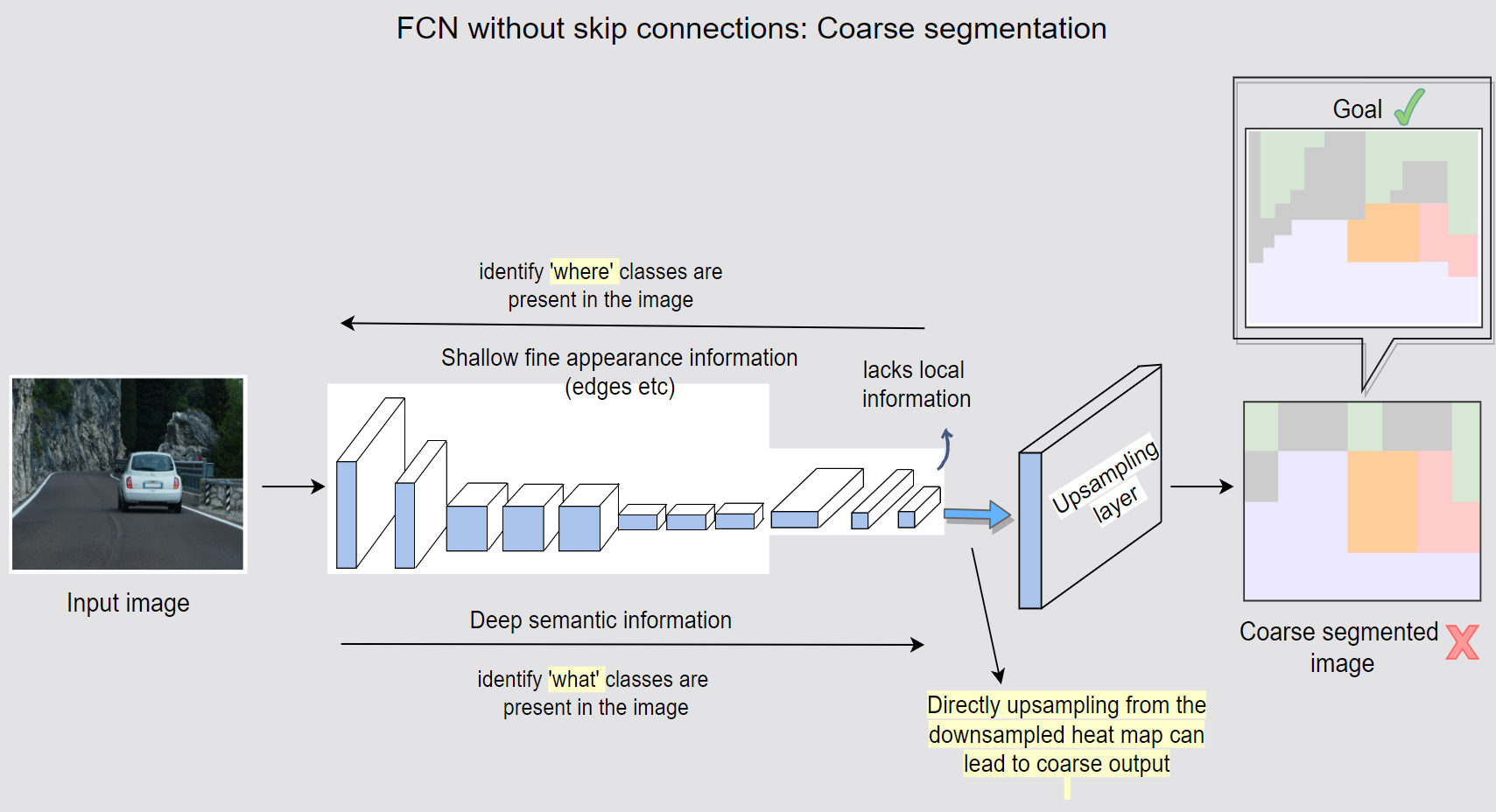
- FCN
- Segmentation is a dense prediction task of pixel-wise classification.
- Major characteristics
- Dynamic input size: the fully connected layers are replaced by convolutional layers at the end of the regular convolution and pooling process.
- Skip connection: the initial layers capturing good edges are connected with the coarse pixel-wise segmentations.
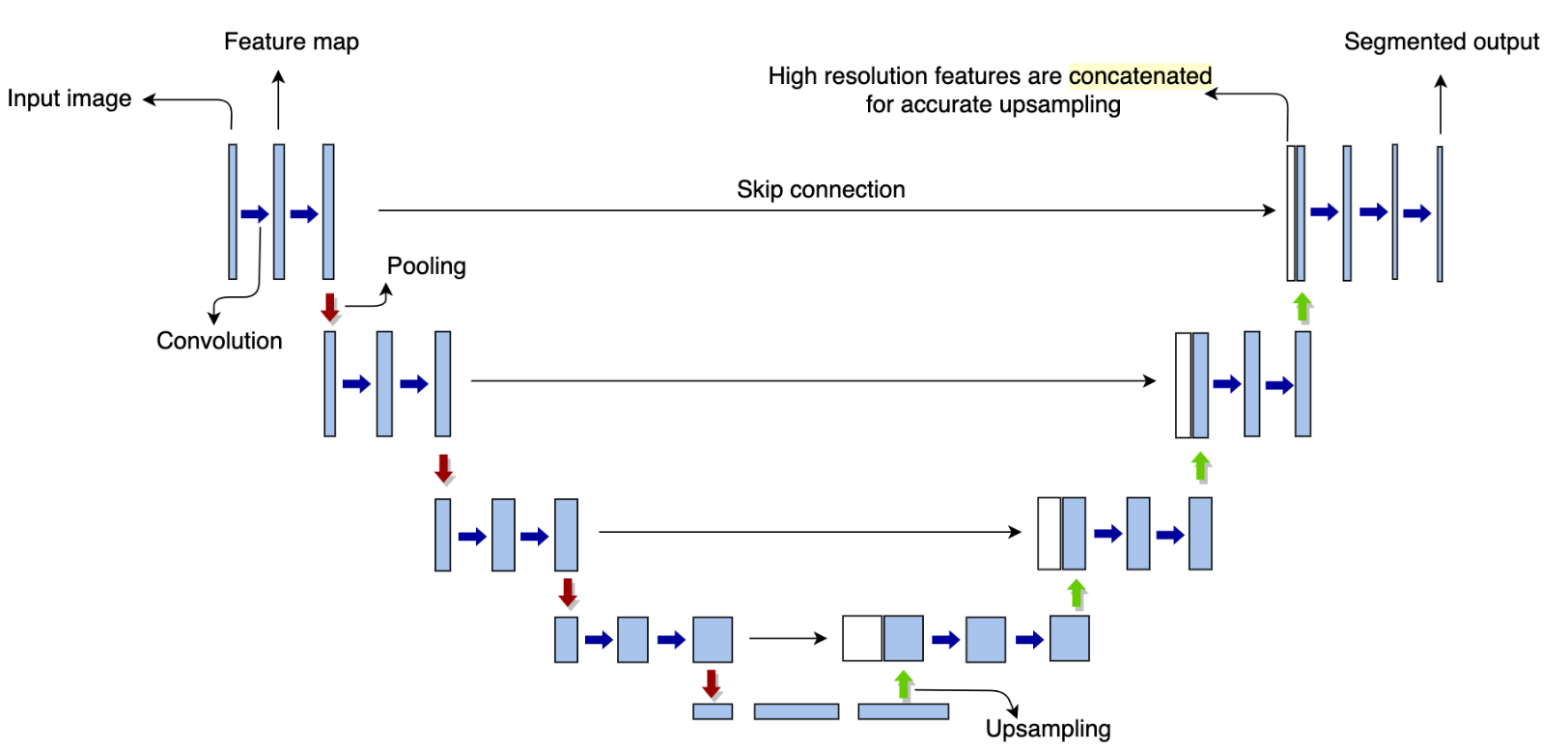
- U-Net
- It is built upon FCN and commonly used for semantic segmentation-based vision applications.
- Downsampling increases info about what objects are present, decreases info about where objects are present.
- Upsampling creates high-resolution segmented output by making use of skip connections.
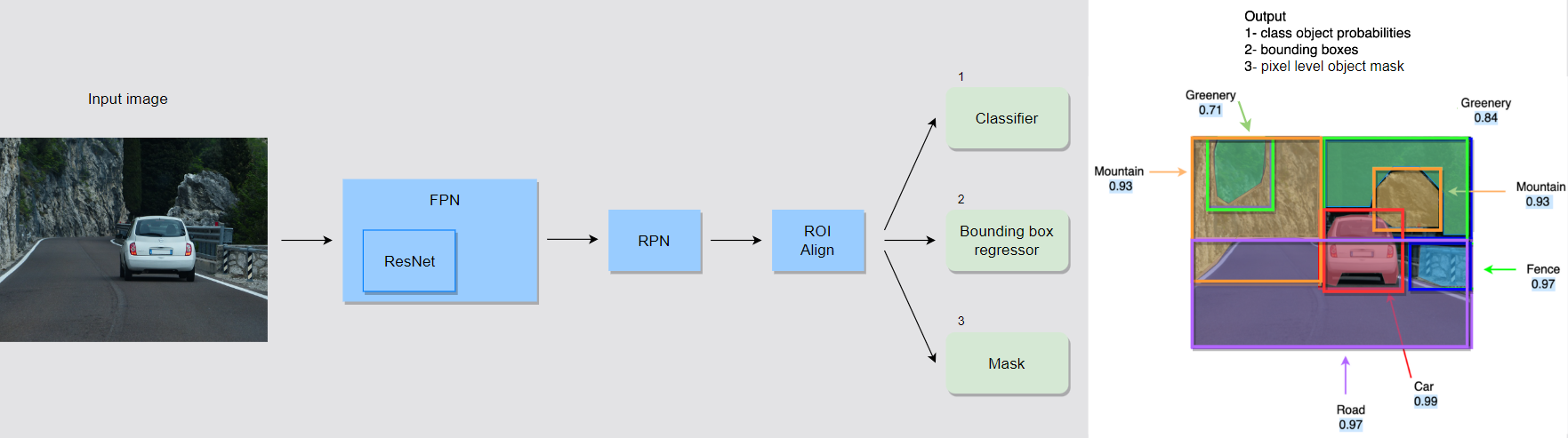
- Mask R-CNN
- It is used for instance segmentation.
- Faster R-CNN for object detection and localization and FCN for pixel-wise instance segmentation of objects.
- Backbone of a CNN followed by a Feature Pyramid Network (FPN) which extracts feature maps at different scale.
- The feature maps are fed to the Region Proposal Network (RPN).
- These proposals are fed to the RoI Align layer that extracts the corresponding ROIs (regions of interest) from the feature maps to align them with the input image properly.
- The ROI pooled outputs are fixed-size feature maps that are fed to parallel heads of the Mask R-CNN.
- Mask R-CNN has three parallel heads to perform Classification, Localization, and Segmentation.
- Transfer learning
- Retraining topmost layer
- Update the final pixel-wise prediction layer in the pre-trained FCN
- This approach makes the most sense when
- The data is limited.
- You believe that the current learned layers capture the information that you need for making a prediction.
- Retraining top few layers
- Update the upsampling layers and the final pixel-wise layer.
- This approach makes the most sense when
- Have a medium-sized dataset
- Shallow layers generally don’t need training because they are capturing the basic image features, e.g., edges
- Retraining entire model
- Laborious and time-consuming
- The dataset has completely different characteristics from the pre-trained network
- Retraining topmost layer
Self-driving Image Segmentation
https://janofsun.github.io/2024/01/17/Self-driving-Image-Segmentation/