Entity Linking System
Problem Statement
Given a text and knowledge base, find all the entity mentions in the text(Recognize) and then link them to the corresponding correct entry in the knowledge base(Disambiguate).
There are two parts to entity linking:
- Named-entity recognition
- Disambiguation
Applications:
- Semantic search
- Content analysis
- Question answering systems/chatbots/virtual assistants, like Alexa, Siri, and Google assistant
Metrics
Offline metrics
Offline metrics will be aimed at improving/measuring the performance of the entity linking component.Name Entity Recognition (NER)
- The tagging scheme: IOB2 (aka BIO)
- B - Beginning of entity
- I - inner token of a multi-token entity
- O - non-entity
- Performance measurement
- $Precision = \frac{no. ;of; correctly ;recognized ;named ;entities}{no. ;of; total ;recognized ;named ;entities}$
- $Recall = \frac{no. ;of; correctly ;recognized ;named ;entities}{no. ;of; named ;entities ;in ;corpus}$
- $F1-score = 2\frac{precisionrecall}{precision+recall} $
- The tagging scheme: IOB2 (aka BIO)
Disambiguation
- Precision
- Recall does not apply here as each entity is going to be linked (to either an object or Null).
Named-entity linking component
F1-score as the end-to-end metric
- True positive: an entity has been correctly recognized and linked.
- True negative: a non-entity has been correctly recognized as a non-entity or an entity that has no corresponding entity in the knowledge base is not linked.
- False positive: a non-entity has been wrongly recognized as an entity or an entity has been wrongly linked.
- False negative: an entity is wrongly recognized as a non-entity, or an entity that has a corresponding entity in the knowledge base is not linked.
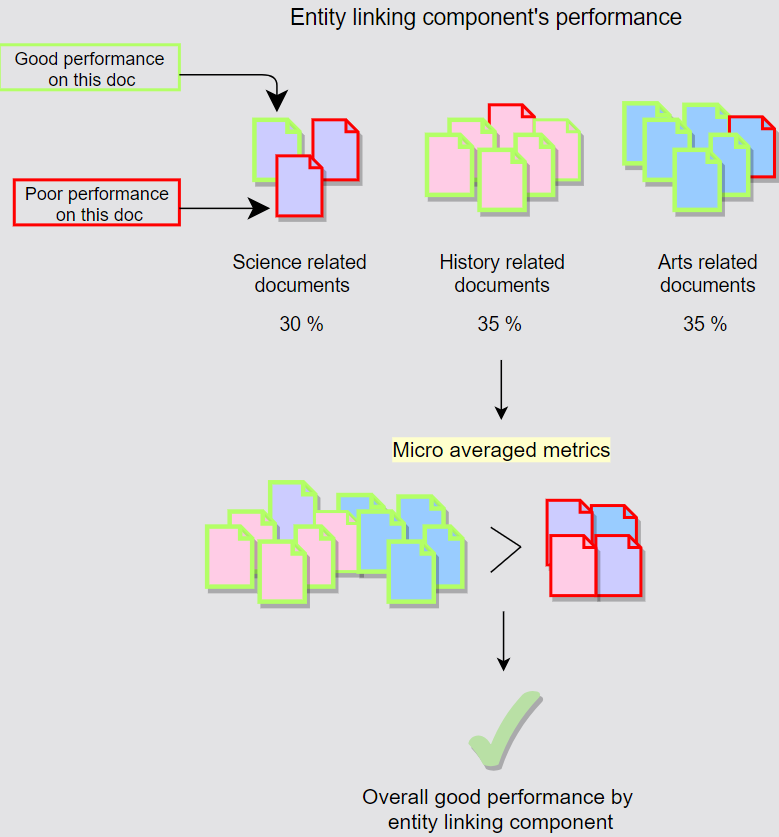
Micro-averaged metrics
- Aggregate the contributions of all documents to compute the average metrics.
- Focus on the overall performance, do not care if the performance is better for a certain set.
- $Precision = \frac{\sum^{n}{i=1}TP_i}{\sum^{n}{i=1}TP_i + \sum^{n}_{i=1}FP_i}$
- $Recall = \frac{\sum^{n}{i=1}TP_i}{\sum^{n}{i=1}TP_i + \sum^{n}_{i=1}FN_i}$
- Micro-averaged F1-score
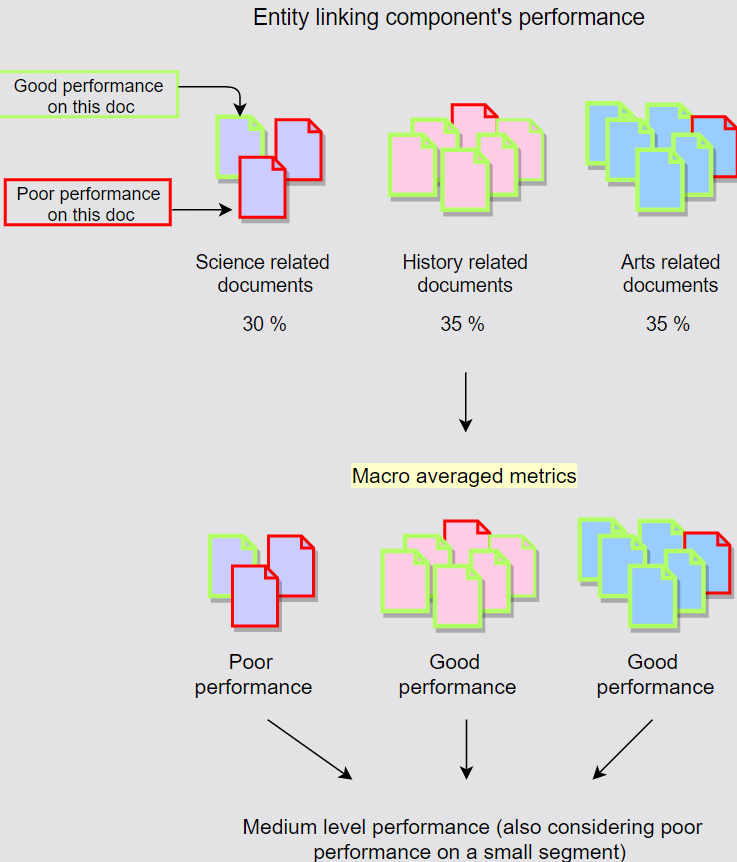
Macro-averaged metrics
- Compute the metric independently for each document and takes the average (equal weightiage).
- $Precision = \frac{\sum_{i=1}^n P_{di}}{n}{where; n= no. ;of; documents,; P{di}= precision; over; document; i}$
- $Recall = \frac{\sum_{i=1}^n R_{di}}{n}{where; n= no. ;of; documents,; R{di}= recall; over; document; i}$
- Macro-averaged F1-score
- Online metrics
Online metrics will be aimed at improving/measuring the performance of the larger system by using a certain entity linking model as its component. (A/B experiments)- Search engines: i.e. session success rate
- Virtual Assistants: i.e. user satisfaction
Architecture
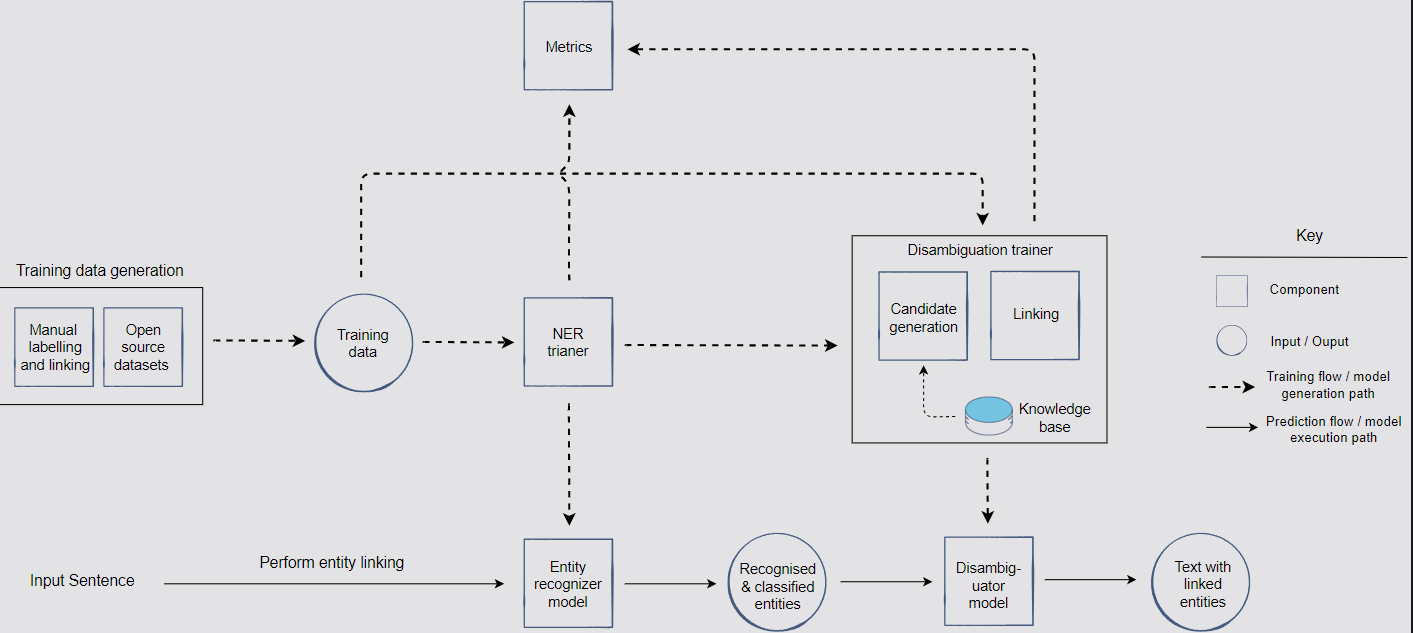
Model generation path
- Named Entity Recognition
- Responsible for building models to recognize entities (i.e. person, organizations)
- Named Entity Disambiguation
- Candidate generation
- Reduce the size of the knowledge base to a smaller subset of candidate entities
- Linking
- Candidate generation
- Metrics
- NER and NED seperately, Entity linking as a whole.
- Named Entity Recognition
Model execution path
Modeling
NER Modeling
- Contextualized text representation
- ELMo
- Raw word vectors: character-level CNN or Word2Vec
- Bi-LSTM with forward/backword pass: “Shallow” bi-directional since the two pass LSTMs are trained independently and concatenated naively, therefore, the left and right contexts can not be used ‘simultaneously’.
- BERT
- The transformer layer will take advantage of contexts from both directions, but with problems - “sees itself indirectly”.
- Prediction Objectives: Masked language modeling (MLM) and Next sentence prediction (NSP)
- ELMo
- Contextual embedding as features
- Utilize contextual embeddings generated by BERT as features (transfer learning) in our NER classifier.
- The model will not be modified, only the final layer output is used as embedding features.
- Fine-tuning embeddings
- Take the pre-trained models and fine-tune them based on our NER dataset to improve the classifier quality.
- Contextualized text representation
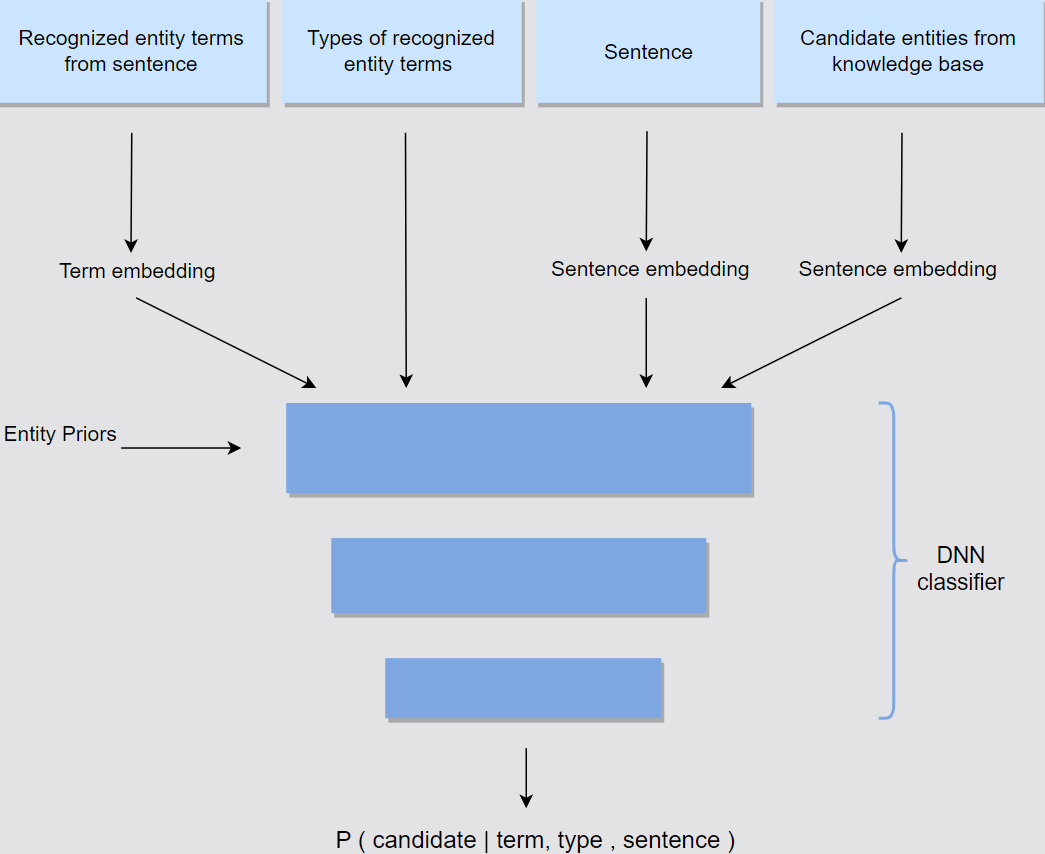
Disambiguation Modeling
Candidate generation
- Higher recall by building an index where terms are mapped to knowledge base entities.
- Methods:
- Based on terms’ names and their concatenations.
- Make use of referrals and anchor text.
- Embedding methods + K Nearest Neighbors for a particular term.
Linking
- Higher precision.
- The prior: for a certain entity mention, how many times the candidate entity under consideration is actually being referred to.
Entity Linking System
https://janofsun.github.io/2024/01/12/Entity-Linking-System/