Ad prediction System
Problem Statement
- How would you build an ML system to predict the probability of engagement for Ads?
- Search engine
- Social media platforms
Metrics
Offline
- Log Loss
- AUC does not penalize for “how far off” predicted score is from the actual label.
- AUC is insensitive to well-calibrated probabilities.
- Calibration measures the ratio of average predicted rate and average empirical rate
- Use cross-entropy loss.
- Log Loss
Online
- Overall revenue
- Revenue is basically computed as the sum of the winning bid value when the predicted event happens.
- Overall ads engagement rate
- Overall revenue
Counter metrics, tracking this to see if the ads are negatively impacting the platform.
Architecture
Advertiser flow
- Query-based targeting
- User-based targeting
- Interest-based targeting
- Set-based targeting
User flow
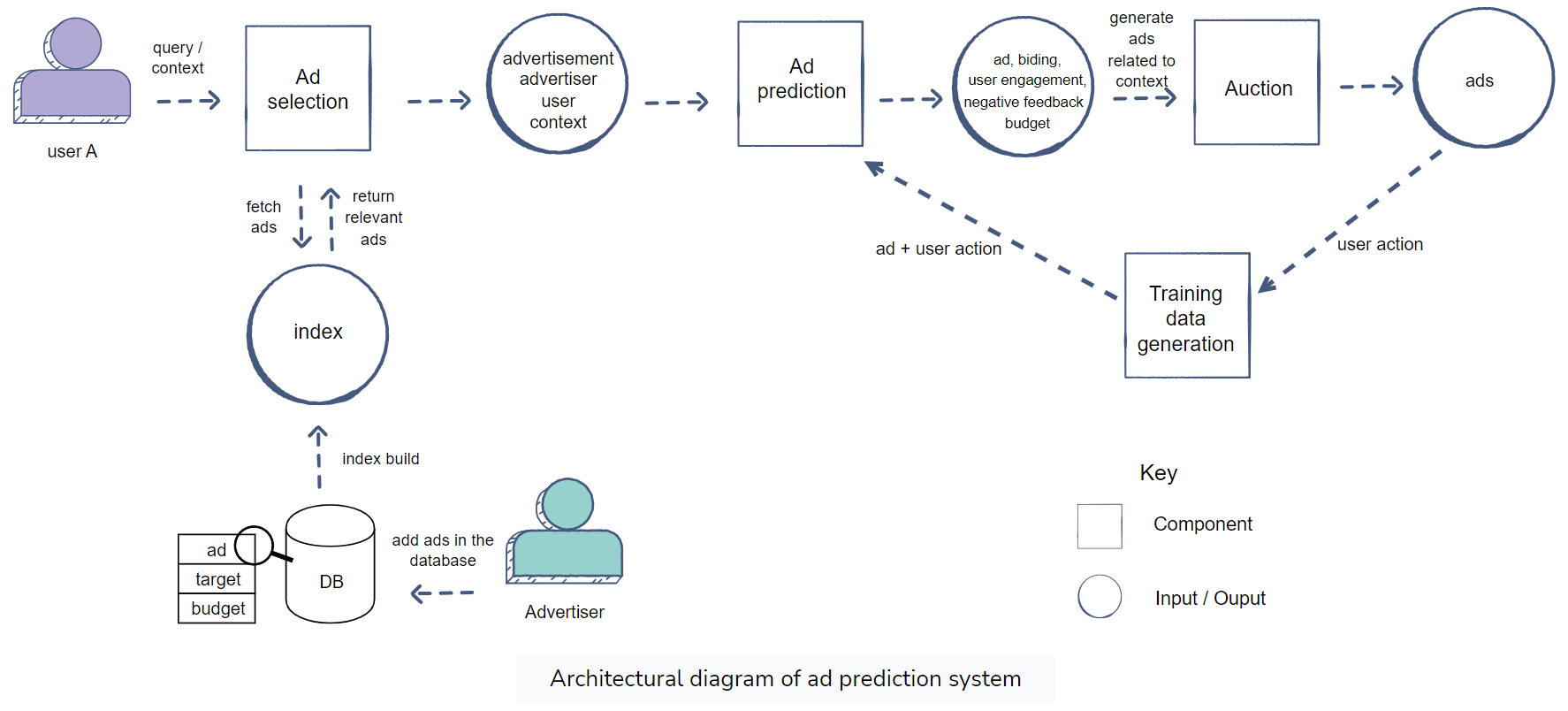
Training Data Generation
- Training data generation through online user engagement
- Advertiser should specify which action to consider positive or negative (ignored or negative feedback).
- Balancing positive and negative examples
- Model Recalibration
- Negative downsampling make our predicted model output be in the downsampling space. It’s critical to recalibrate our score before sending then to auction.
- $q = \frac{p}{p+(1-p)/w}$
- $q$ is the re-calibrated prediction score
- $p$ is the prediction in downsampling space
- $w$ is the negative downsampling rate
- Train test split
Ad Selection
The main goal of the ads selection component is to narrow down the set of ads that are relevant for a given query.
- Phase 1: Quick selection of ads for the given query and user context according to selection criteria
- Building an in-memory index to store the ads.
- Phase 2: Rank these selected ads based on a simple and fast algorithm to trim ads.
- The eventual ranking of ads is based on $(bid)$ $*$ $(prior\ CPE \ Score)$ (CPE - cost per engagement).
- Score boost (a slightly higher score), for a new ad or advertiser (where the system don’t have good prior scores).
- Time decay
- Phase 3: Apply the machine learning model on the trimmed ads to select the top ones.
- System scale:
- The number of partitions depend of the size of the index
- The system load (QPS) decides how many times the partition is replicated
Ad Prediction
Ad prediction is responsible for predicting a well-calibrated engagement and quality score of ads.
Ads are generally short-lived. So, our predictive model is going to be deployed in a dynamic environment where the ad set is continuously changing over time.
- Keeping refreshing the model with the latest impressions and engagements after regular intervals.
- Models
- Auto non-linear feature generation
- The easy model is to update it using SGD using mini-batches in logistic regression.
- It relies on manual effort to create complex feature crosses.
- Combine additive trees and neural networks to generate features, then feeding into logistic regression.
- Auto non-linear feature generation
Auction
- Bid: an advertiser places for that ad.
- User engagement rate
- Ad quality score
- $Ad\ rank\ score = Ad\ predicted\ score\ *\ bid$
- $CPE = \frac{Ad\ rank\ of\ ad\ below}{Ad\ rank\ score}+0.01$ where $CPE$ represents cost per engagement or cost per click $CPC$.
- A general principle is that the ad will cost the minimal price that still allows it to win the auction.
Pacing
Pacing an ad means evenly spending the ad budget over the selected time period.
Feature Engineering
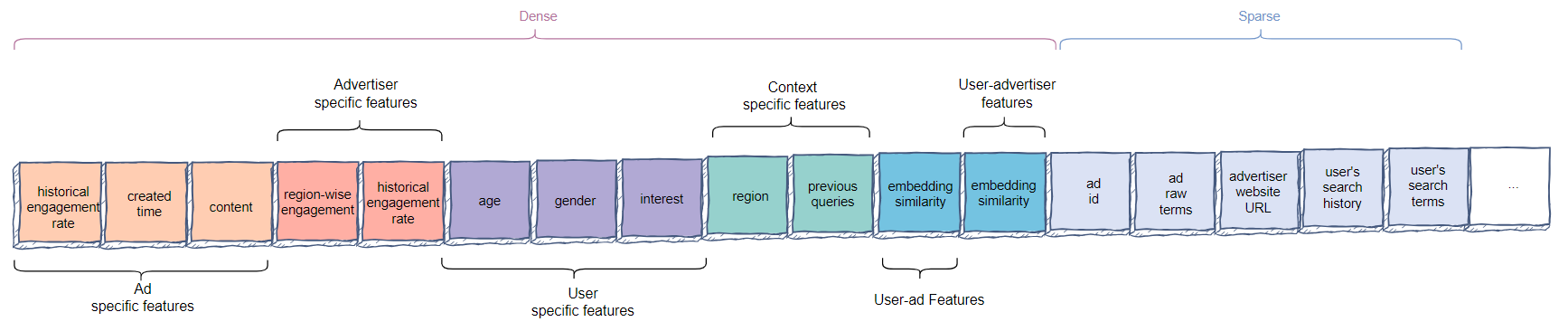
- Ad specific features
- ad impressions: selecting a cut-off point until which we want to consider the impressions.
- Advertiser specific features
- User specific features
- Context specific features
- User-ad cross features
- User-advertiser cross features
Example
Problem statement:
- Build a machine learning model to predict if an ad will be clicked.
Metrics:
- Offline:
- Focusing more on ml metrics instead of revenue metrics or CTR metrics.
- Normalized Cross-Entropy (NCE): predictive logloss divided by the cross-entropy of the background CTR.
- Online:
- Revenue lift: Percentage of revenue changes over a period of time.
- Offline:
Model:
Calculation&&Estimation
Assumptions:
- $40$k ad requests per second or $100$ billion per month
- Each observation (record) has hundreds of features, and it takes $500$ bytes to store.
Data Size:
- Historical ad click data includes [user, ads, click_or_not]
- An estimated 1% CTR (1 billion): $100 * 10^{12} * 500 = 5 * 10^{16} $bytes or $50$ PB.
Scale: $100$ million users
High-level design
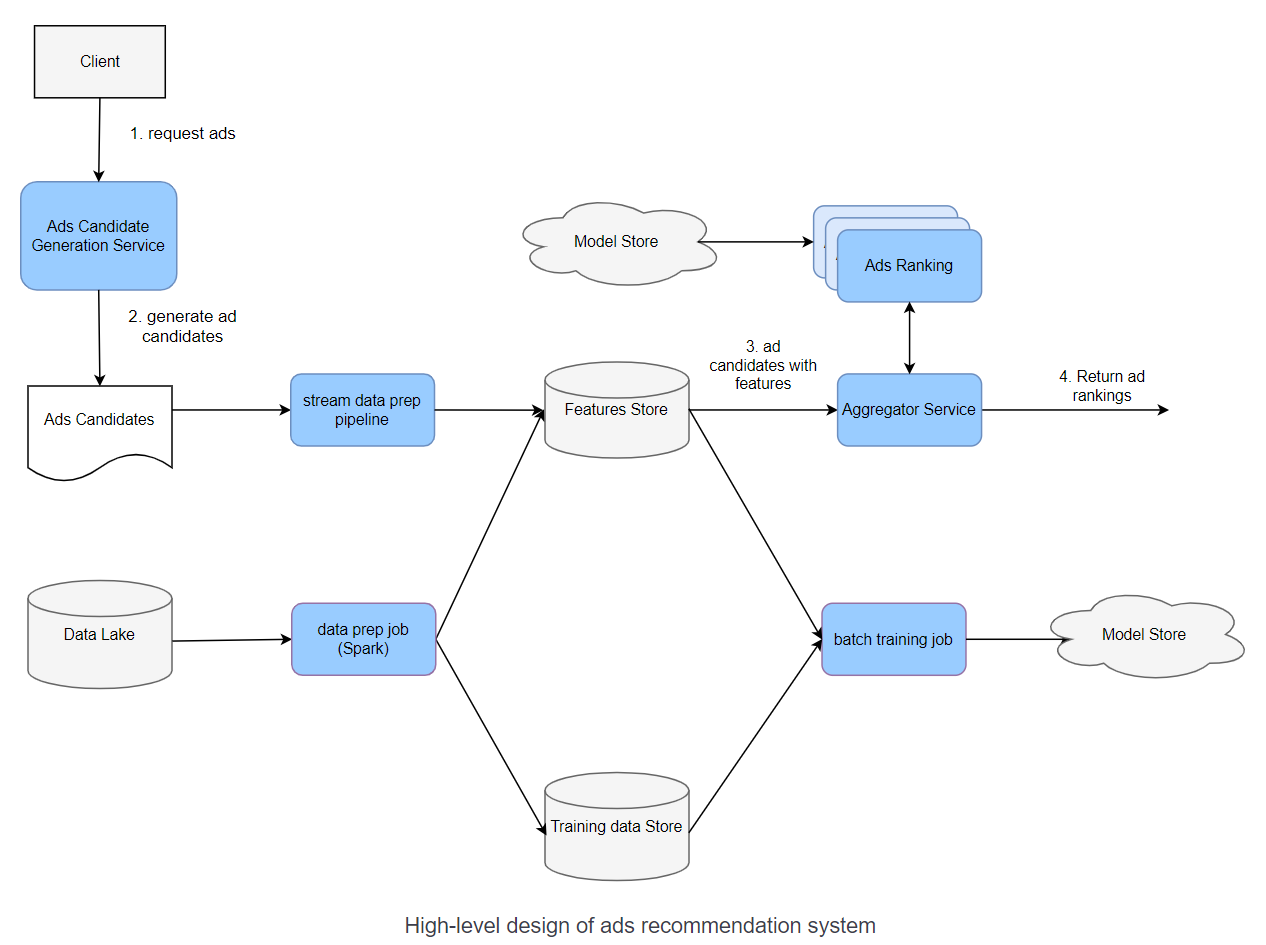
- Data Lake
- Batch data prep
- Batch training jobs
- Model store
- Stream data prep pipeline
- Model Serving
- Aggregator Service:
Ad prediction System