Feed Based System
Problem Statement
Design a Twitter with 500 million daily active users feed system that will show the most relevant tweets for a user based on their social graph.
Metrics
- Topline is that it’s scientific as well as a business-driven decision. Overall user engagements: comments, likes, and retweets. Business-driven decision: time spent on Twitter.
- Weighted engagement + Normalized Score (divided by the total number of active users). A higher score equates to higher user engagement.
Architecture
Tweet Selection
- New Tweets + Unseen Tweets: To fetch a mix of newly generated Tweets along with a portion of unseen Tweets from the cache.
- Edge case: User returning after a while
- The pool of Tweets keeps on increasing so a limit needs to be imposed on the number of Tweets.
- Edge case: User returning after a while
- Network Tweets + interest/popularity-based Tweets
- Two-dimensional scheme: selecting network Tweets + potentially engaging Tweets.
- Benefits
- Helpful for Bootstrap problems
- To increase the discoverability on the platform and help grow the user’s network.
Ranking
- Logistic regression
- Pros and Cons:
- it is fast to train
- the major limitation of linear models is that it assumes linearly exists between the input features and prediction.
- Approaches
- Train a single classifier for overall engagement.
- Train seperate models for each engagement action based on production needs (i.e. P(like), P(comments), P(tweet)).
- Pros and Cons:
- MART (multiple additive regression trees)
- Tree-based models don’t require a large amount of data as they are able to generalize well quickly.
- Train a single model for the overall engagement.
- Train specialized predicators to predict different kinds of engagement.
- Overall engagement + individual predictor of each engagement action -> to build one common preictor
- P(engagement) and share its output as input into all of your predictors.
- Tree-based models don’t require a large amount of data as they are able to generalize well quickly.
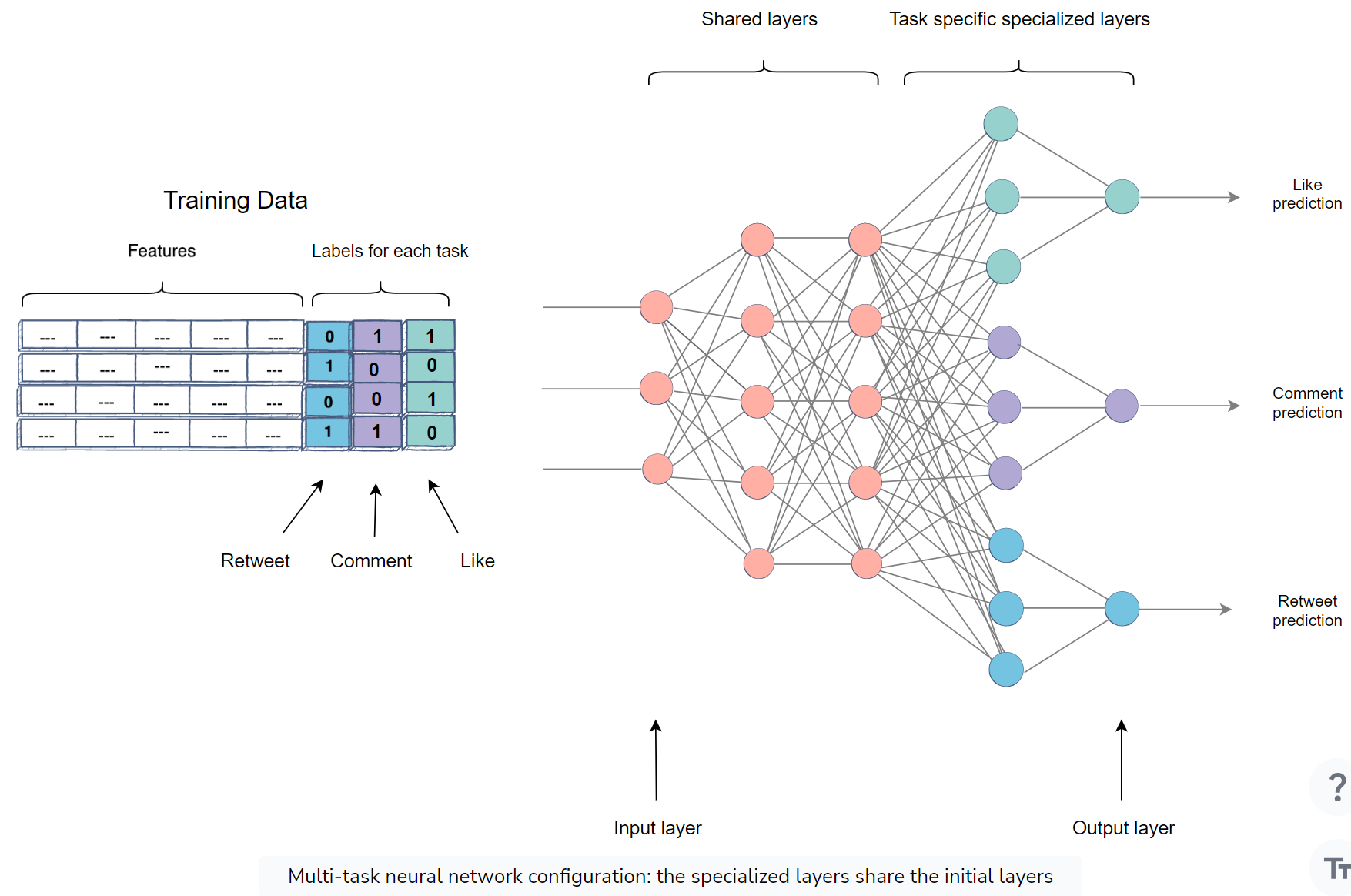
- Deep Learning
- Seperate neural networks
- Multi-task neural networks
- Stacking models and online learning
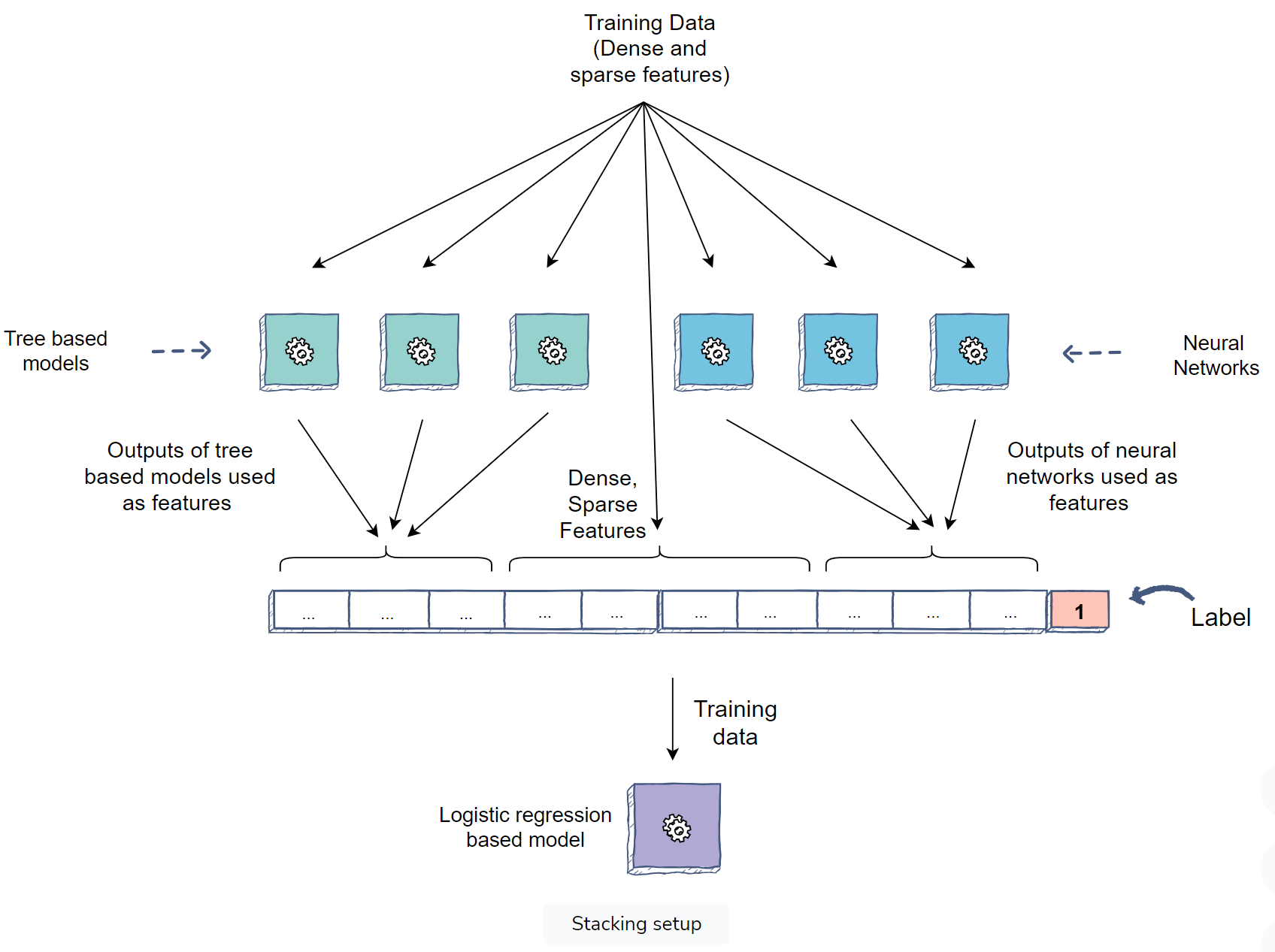
- Training tree-based models and neural networks to generate features that we will utilize in a linear model (logical regression)
- Trees generate features by using the triggering of leaf nodes (result in a boolean feature).
- Plug-in the output of the last hidden layer as features into the logistic regression models.
- Logistic regression: this helps the model to re-learn the weight of all tree leaves as well.
- Main advantage: online learning
- Using real-time online learning with logistic regression so that we can utilize sparse features to learn the interactions.
- Training tree-based models and neural networks to generate features that we will utilize in a linear model (logical regression)
Training Data Generation
- Training data generation through online user engagement
- Balancing positive and negative samples
- Randomly downsample
- Train test split
- We are building models with the intent to forecast the future.
Feature Engineering
The machine learning model is required to predict user engagement on user A’s Twitter feed.
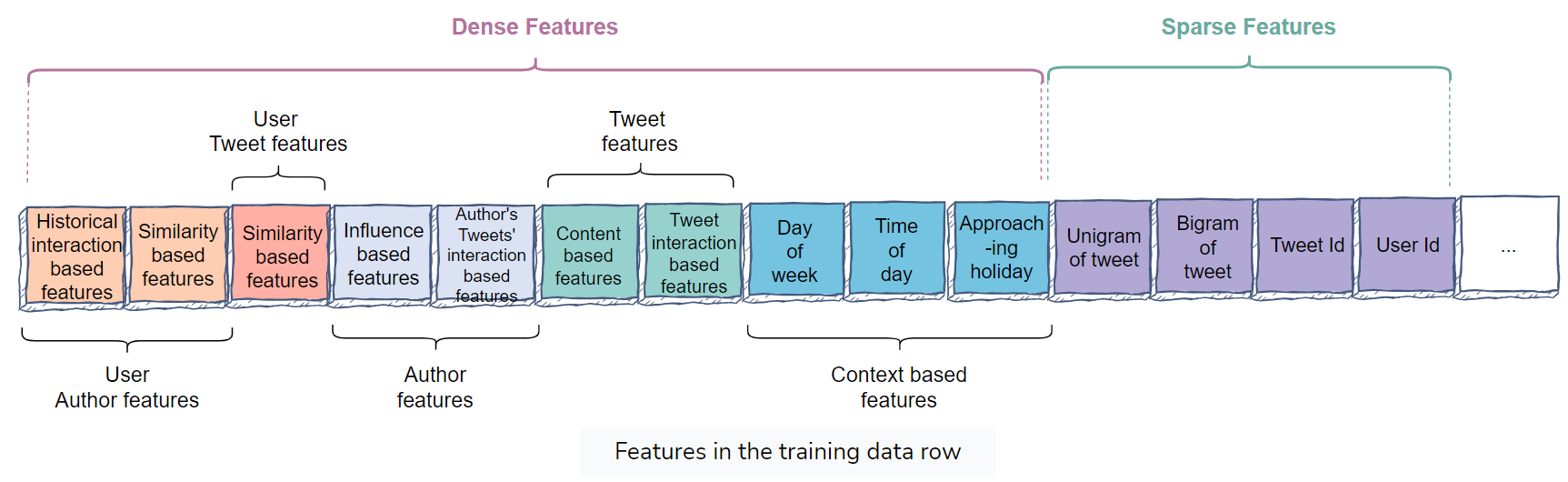
Dense features
- User-author features
- User-author historical interactions
- author_liked_posts_3months
- author_liked_posts_count_1year
- User-author similarity
- common_followees
- topic_similarity
- tweet_content_embedding_similarity
- social_embedding_similarity
- User-author historical interactions
- Author features
- Author’s degree of influence
- is_verified
- author_social_rank
- author_num_followers
- follower_to_following_ratio
- Historical trend of interactions on the author’s Tweets
- author_engagement_rate_3months
- author_topic_engagement_rate_3months
- Author’s degree of influence
- User-Tweet features
- topic_similarity
- embedding_similarity
- Tweet features
- Features based on Tweet’s content
- Tweet_length
- Tweet_recency
- is_image_video
- is_URL
- Features based on Tweet’s interaction
- num_total_interactions
- caveat: We need to apply a simple time decay model to weight the latest interaction more than the ones that happened some time ago.
- Seperate features for different engagements
- num_total_interactions
- Features based on Tweet’s content
- Context-based features
- day_of_week
- time_of_day
- current_user_location
- lastest_k_tag_interactions
- approaching_holiday
- User-author features
Sparse features
- unigrams/bigrams of a Tweet
- user_id
- tweets_id
Diversity
- Introducing the repetition penalty as adding negative weights
- To bring the Tweet with repetition three steps in the sorted list.
Feed Based System