Intro to AE and VAE
Discrimitive | Generative | Latent Models
- Discrimitive: it is to learn a mapping between the data and the classes (i.e. learning from historical data and then predicting the probability of A being A or B by extracting its features.).
- Generative: to learn a probability distribution over the data points without external labels (i.e. learning two differnent models of A and B, then, features are extracted from one object (A or B), and these features are fed into the two models to see the probability. The one with the higher probability determines the result.)
- Latent: it can be understood as dimension reduction.
- Generation: refers to the process of computing the data point $x$ from the latent variable $z$.
- Inference: is the process of finding the latent variable $z$ from the data point $x$ and is formulated by the posterior distribution

AutoEncoders
The goal of the standard autoencoder is to reconstruct the input data.
- In general, it consists of an encoder for compression and a decoder for reconstruction.
- Vanilla autoencoders are trained using a reconstruction loss (i.e. the L2 distance between the input and output).
However, the autoencoder is not good at generalizing unseen dataset.
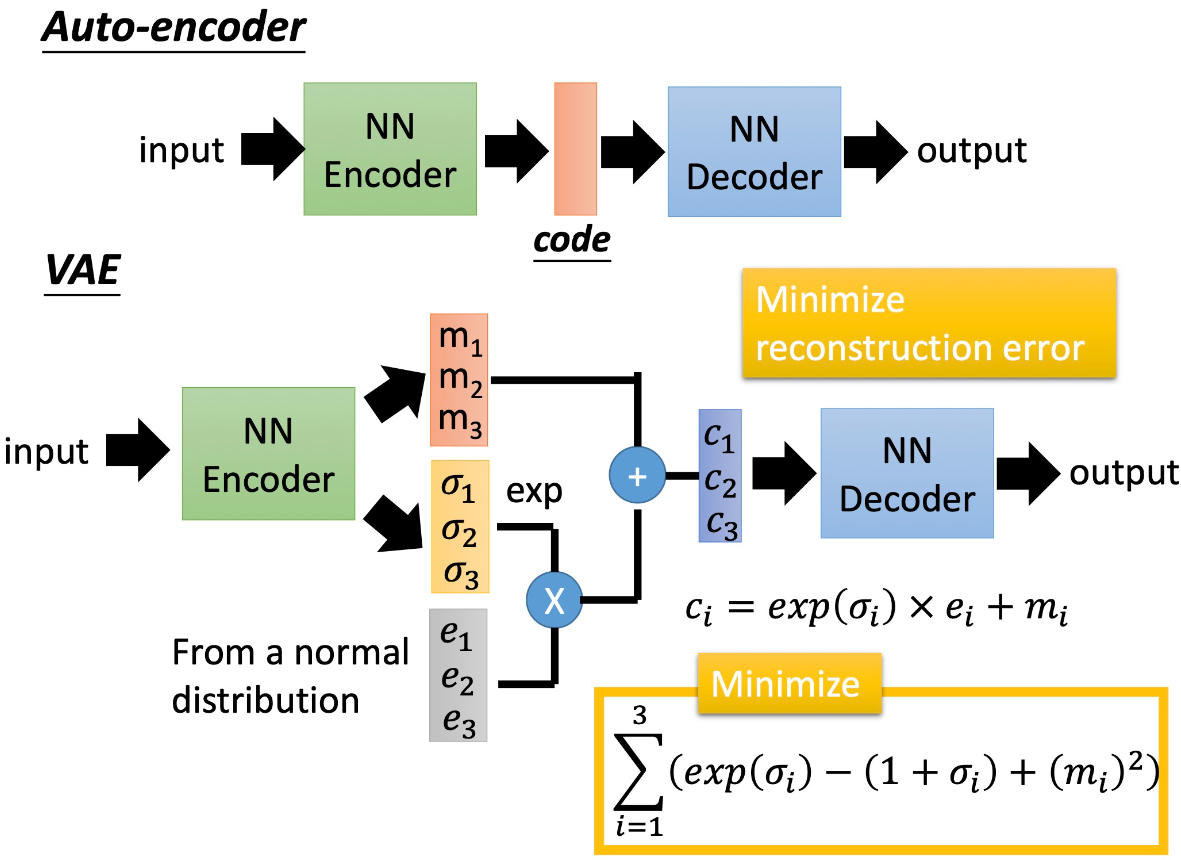
Variational AutoEncoders
In simple terms, a variational autoencoder is a probabilistic version of autoencoders. The loss function of VAE consists of two parts:
- MSE loss to minimize the difference between the output and the input.
- In order to avoid overfitting and make the decoder be able to generate unseen data, constraints must be imposed on μ and σ to make the normal distribution they form as close as possible to the standard normal distribution. (KL divergence)
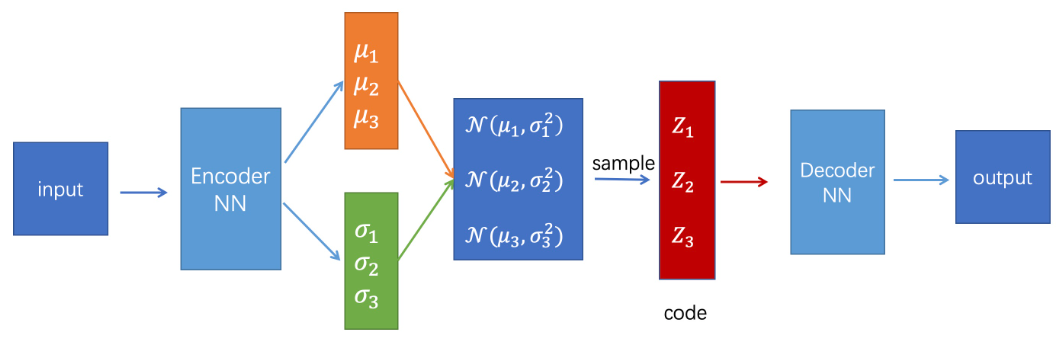
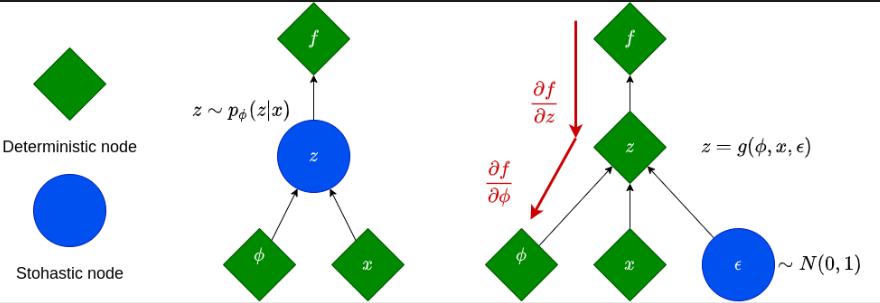
Note that the code above is obtained through sampling from a normal distribution. A probability distribution is fully characterized by its parameters (mean and var). This kind of stochastic operation cannot be computed to get the gradients. In other words, we cannot backpropagate through a sampling operation. This is exactly the heart of learning to train variational autoencoders.
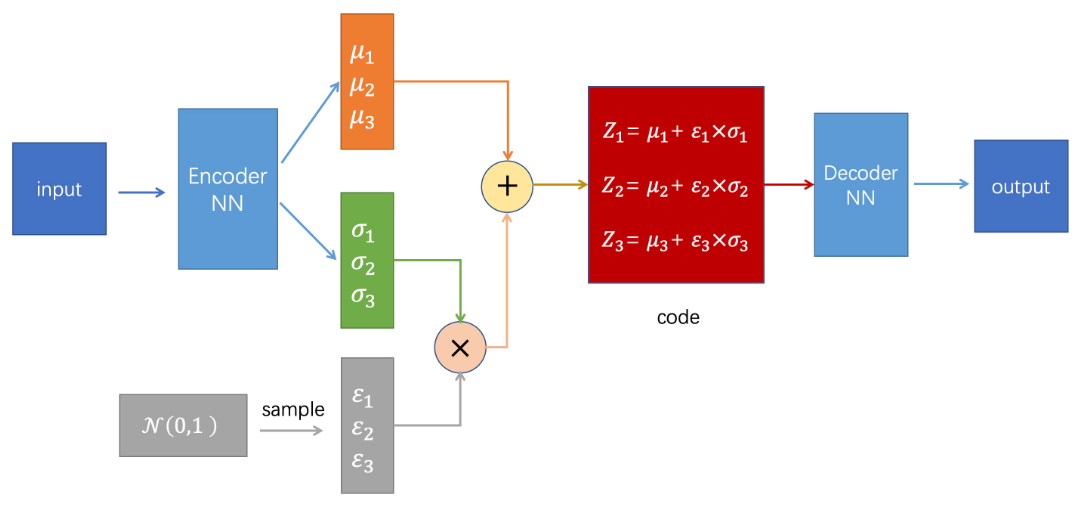
Reparameterization
In this case, we use the reparameterization trick. The abstract idea is to keep a fixed part stochastic with epsilon and train the mean and the standard deviation. Next, we will backpropagate through the mean μ and the standard deviation σ that are the outputs of the encoder.
$$
z=μ+σϵ , ϵ∼N(0,1)
$$
Again, the epsilon term introduces the stochastic part and is not involved in the training process.
References ⭐
Intro to AE and VAE