Layer Norm | Batch Norm | Instance Norm | Group Norm
LB | BN | IN | GN in NLP
- Batch Norm: Normalizes each feature across the entire batch. Rarely used in NLP, because it relies on consistent sequence lengths and large batch sizes, and is sensitive to padding.
- Layer Norm: Normalizes across the feature dimension for each token independently, making it suitable for variable-length sequences
- Instance Norm: Originally used in computer vision to normalize each channel within each sample. It is not commonly applied in NLP tasks.
- Group Norm: Splits the feature (embedding) dimension into groups and performs normalization within each group. It’s occasionally used in NLP when LayerNorm is replaced for better generalization under small-batch or resource-constrained settings.
🤖 Scenarios for BatchNorm vs LayerNorm
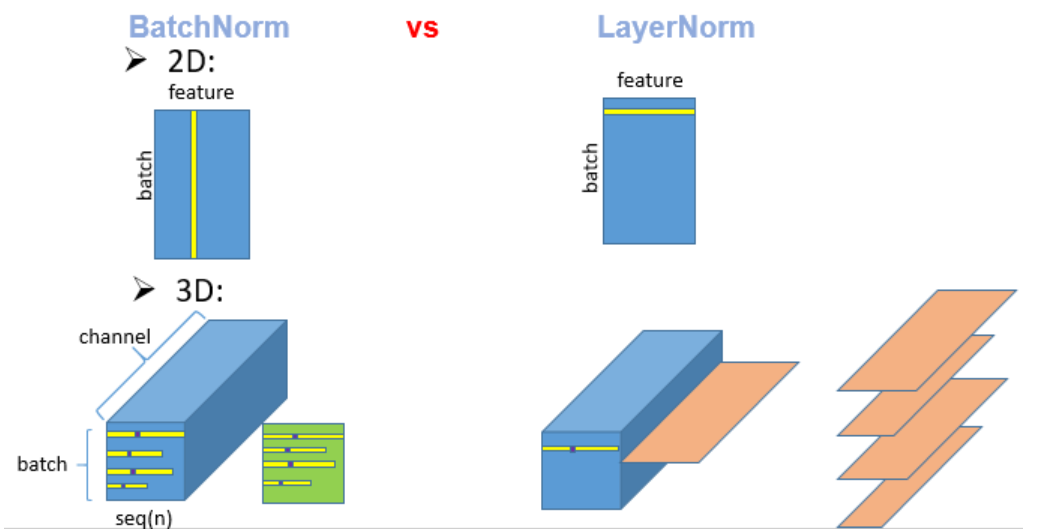
In terms of operations, BN computes one mean/variance per channel across the entire batch and spatial dimensions, while LN computes mean/variance within each individual sample, across the feature dimension (generally the last dimension dim=-1), independently of other samples and tokens.
- In ML/CV tasks, data often consists of each column representing a feature, and the processed data typically has interpretability, with different units and properties across columns, hence BN is more commonly used in machine learning tasks.
- In NLP, Transformer-based models generally represent data as [batch, seq_len, embedding_dim]. LayerNorm is preferred because it normalizes each token’s embedding independently, preserving token-wise semantics and being robust to variable-length sequences without relying on batch-level statistics.
1 | import torch |
🧠 Summary Comparison: BatchNorm vs LayerNorm
| Feature | BatchNorm | LayerNorm |
|---|---|---|
| Depend on batch size? | ✅ Requires cross-sample statistics | ❌ Independent of batch size |
| Handles variable-length sequences? | ❌ Padding affects statistics | ✅ Each token is normalized independently |
| Inference stability? | ❌ Uses moving average, can be unstable | ✅ Consistent behavior during inference |
| Multi-GPU / small batch stability? | ❌ Very unstable | ✅ Not affected at all |
| Suitable for Transformer architecture? | ❌ Breaks token-wise independence | ✅ Perfectly matches token-wise design |
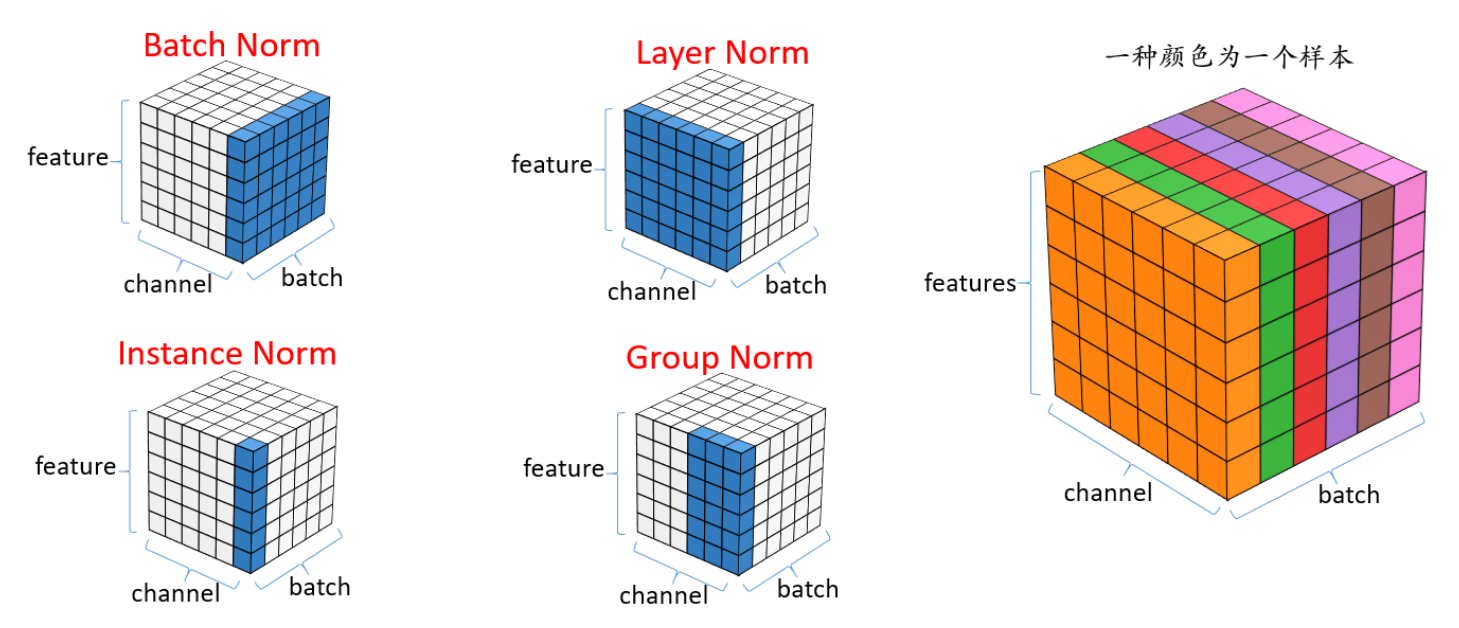
LB | BN | IN | GN in CV
Considering feature maps with shape (N, C, H, W):
- N: batch size
- C: number of channels
- H, W: spatial dimensions
Different normalization methods apply statistics over different dimensions:
Batch Norm (BN): Normalizes each channel using statistics computed across the batch (N) and spatial dimensions (H, W). Each channel shares a single mean and variance across all samples and locations.
Layer Norm (LN): Normalizes across all channels and spatial dimensions within each sample, making the entire feature map of a sample zero-mean and unit-variance.
Instance Norm (IN): Normalizes each channel independently per sample, using only the spatial dimensions (H, W) of that channel.
Group Norm (GN): Divides channels into groups (e.g., 32 groups), then normalizes the features within each group across spatial dimensions, per sample.
🤖 Scenarios for Instance Norm and Group Norm:
- Instance Norm: it is particularly suited for style transfer tasks and image generations. Instance normalization helps maintain the individuality and unique style of each image, free from batch-level interference.
- Group Norm: Particularly effective in scenarios with small batch sizes or batch size = 1, such as object detection and image segmentation. By normalizing over groups of channels within each sample, it provides stable training dynamics and better generalization where BatchNorm may fail.
1 | class InstanceNorm(nn.Module): |
References ⭐
Layer Norm | Batch Norm | Instance Norm | Group Norm
https://janofsun.github.io/2023/11/14/Layer-Norm-Batch-Norm-Instance-Norm-Group-Norm/