Depthwise Separable Convolutions
Inception Modules
In a convolutional layer, a single convolution kernel is tasked simultaneously mapping cross-channel correlations and spatial correlations. The inception module is to make this process easier and reduce computational expense by decoupling the depthwise convolution (i.e. spatial convolution over each channel) and pointwise convolution (i.e. 1x1 kernel for cross-channel operations).
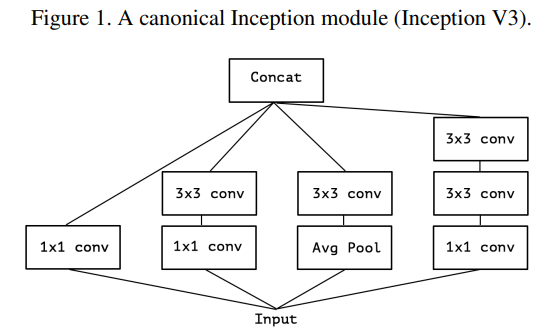
A typical Inception module includes the following components:
- 1x1 cross-channel operation for the input feature map.
- Multisized Convolutional Kernels (1x1, 3x3, 5x5): Convolutional kernels of various sizes are applied simultaneously to the input feature maps to capture spatial features at different scales.
- Pooling Layer: It helps to capture the context of features and reduce the overfitting.
- Channel Concatenation: The output of the module contains aggregated information from features at all scales.
Depthwise Seperable Convolution
As introduced from Xception, a depthwise seperable convolution can be understood as an Inception module with a maximally large number of towers.
- The DSC provides dedicated processing for each channel, instead of sharing the same convolutional kernels across multiple channels.
- Xception architecture is a linear stack of depthwise separable convolution layers with residual connections.
Differences between the Inception Modules and the Depthwise Separable Convolution
- The order of the operations: depthwise separable convolutions as usually implemented (e.g. in TensorFlow) perform first channel-wise spatial convolution and then perform 1x1 convolution, whereas Inception performs the 1x1 convolution first.
- The DSC preserves the independence of spatial features by processing the spatial information of each channel first.
- The Inception starts with the fusion and reduction of features, followed by the extraction of spatial features.
- Non-linearity: The presence or absence of a non-linearity after the first operation. In Inception, both operations are followed by a ReLU non-linearity, however depthwise are able convolutions are usually implemented without non-linearities.
- The ReLU in Inception following each convolution operation is to increase the network’s non-linear capability in order to capture more complex features and patterns.
- The ReLU in DSC might not be used between the depthwise (spatial) and the pointwise (1x1) convolution. This is because non-linear activation function could potentially disrupt the feature representation between two consecutive convolutional steps. The main advantage of DSC is to reduce computational load and the number of parameters.
Code for Xception
As demonstrated in the paper, the architecture can be displayed as the following.
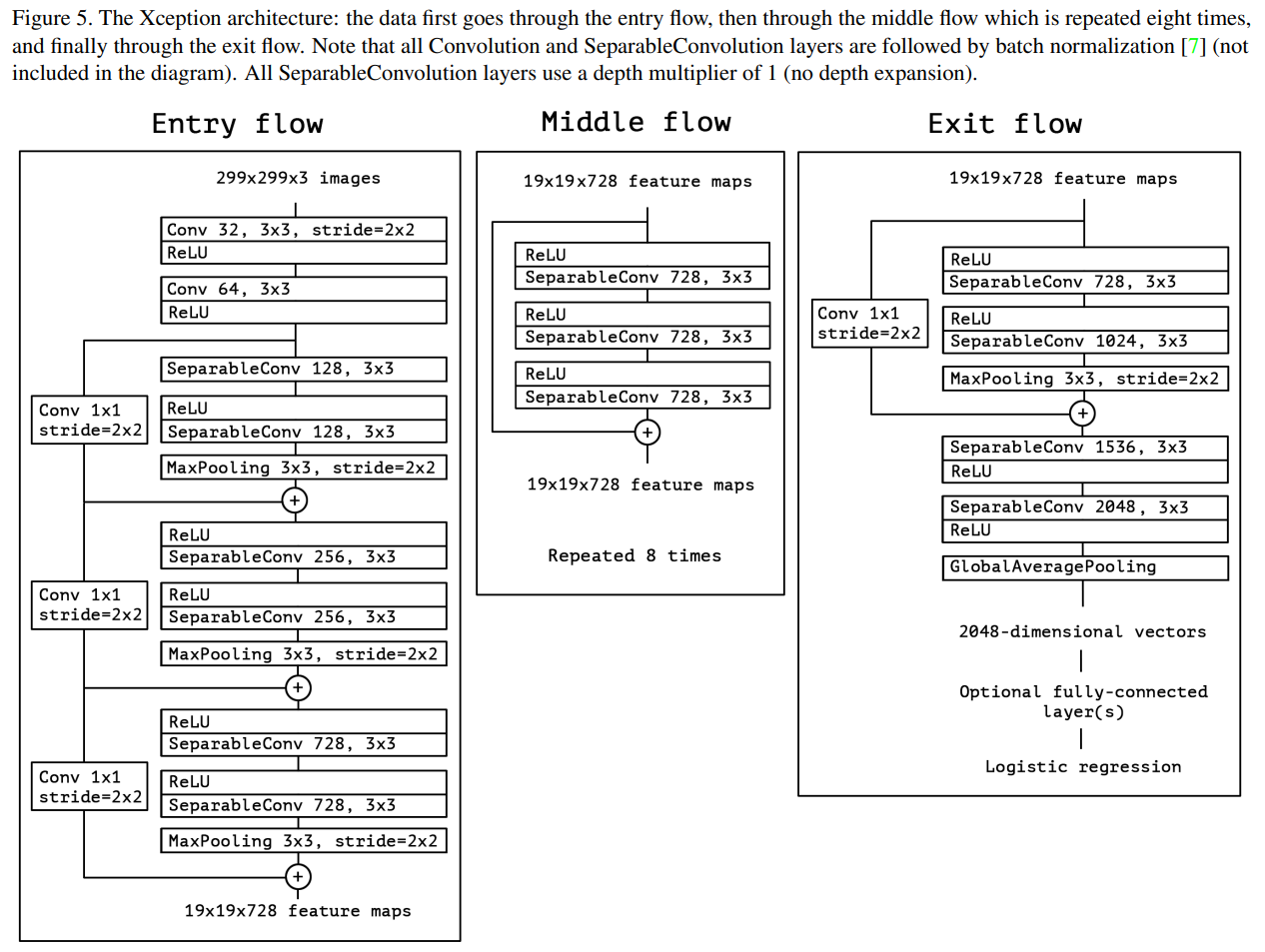
This model can be accessed directly from Keras. Some arguments in the Keras model need to be explained:
- include_top: this parameter is commonly used to determine whether to include the fully connected layers at the top of the model. This option is particularly important when using pretrained networks.
Adaptability to Specific Tasks: Pretrained networks are typically trained on large datasets (like ImageNet) for recognizing thousands of categories.
Feature Extractor: When the top fully connected layers are not included, the model can be used as a feature extractor.
Fine-Tuning: In transfer learning, we usually only train the newly added layers while freezing the rest of the pretrained model.
- pooling: Optional pooling mode for feature extraction when include_top is False.
References ⭐
Depthwise Separable Convolutions
https://janofsun.github.io/2023/11/08/Depthwise-Separable-Convolutions/